equinor=['Statoil', 'EQNR', 167.554919090282, 376883380048.5, 6.14609823076753, 0.617893838660362]
dnb=['DNB', 'DNB', 164, 259169427140, 11.1121822724349, 0.914999939276725]
telenor=['Telenor', 'TEL', 148.737572948101, 227115017138.4, 13.0211568133471, 0.715300723576896]
marine_harvest=['Marine Harvest', 'MHG', 225.589705235372, 118004750966.2, 21.6878893009616, 0.440427599611273]
aker_bp=['Aker BP', 'AKERBP', 272.499264741749, 103712690592, 26.7636558040214, 0.722568840028356]
yara_international=['Yara International', 'YAR', 333.328922090651, 99481443032.4, 86.741957363663, 0.465057636887608]
gjensidige_forsikring=['Gjensidige Forsikring', 'GJF', 172.830508474576, 92125000000, 24.9404407385348, 0.847890127134592]Lister
4 - lister, oppslag og numpy
En liste er en datastruktur, som igjen er en organisering av objekter. Slike datastrukturer er helt sentralt i alle programmeringsspråk, og alle språk har ulike typer strukturer til ulike formål. I noen datastrukturer kan du putte alle typer objekter sammen, slik som tekst, funksjoner og tall og nye datastrukturer.
I andre datastrukturer kan du kun putte tall. Slike datastrukturer er vanligvis det vi i matematikken kaller vektorer og matriser. Disse kommer vi tilbake til når vi skal snakke om Numpy.
Det vi skal se på først er de innebygde datastrukturene til Python. Alle de innebygde strukturene kan inneholde alle typer objekter, men de har noen viktige egenskaper som skiller dem: * list (liste): Hvert element har en bestemt plassering i listen, Tilgang fås ved å referere til plasseringen (indeksen) i form av et heltall int. * Tuple: Lik lister, men kan ikke forandres når den er skapt. Hovedsakelig til bruk i forbindelse med funksjoner. * dict(dictionary, oppslag): Elementene har ikke en bestemt plassering. Tilgang fås ved å referere til en nøkkel (vanligvis en streng str)
Vi starter med å se på lister.
Lister lages med klammeparenteser. Her er noen lister med navn, forkortelse (Ticker), aksjekurs, markedsverdi, PE og gjeldsgrad for noen aksjer på Oslo Børs. Tallene er fra 27. november 2020 (kilde https://tilon.uit.no).
PE er “Price/Earnings”, som er forholdet mellom selskapenes inntjening og prisen. Gjeldsgrad er hvor stor andel av total kapital som er gjeld. Det som ikke er gjeld er egenkapital.
Eksempel 1:
Vi kan nå få tilgang til listene ved å referere til plasseringen med klammeparentes. Om vi vil referere navnet til equinor, som ligger på plass 0, kan vi for eksempel skrive equinor[0] (første element er alltid på plass 0 i Python):
equinor[0]'Statoil'Vi ser at navnet er feil, dette er det gamle navnet til Equinor. Dette kan vi enkelt endre ved å sette element 0 i equinor-listen lik 'Equinor':
Eksempel 2:
print(equinor)
equinor[0]='Equinor'
print(equinor)['Statoil', 'EQNR', 167.554919090282, 376883380048.5, 6.14609823076753, 0.617893838660362]
['Equinor', 'EQNR', 167.554919090282, 376883380048.5, 6.14609823076753, 0.617893838660362]Men vi kan legge hvilke som helst objekter inn i en liste, så vi kan også lage en liste av listene over.
Eksempel 3:
stocks=[equinor,dnb,telenor,marine_harvest,aker_bp,yara_international,gjensidige_forsikring]
stocks[['Equinor',
'EQNR',
167.554919090282,
376883380048.5,
6.14609823076753,
0.617893838660362],
['DNB', 'DNB', 164, 259169427140, 11.1121822724349, 0.914999939276725],
['Telenor',
'TEL',
148.737572948101,
227115017138.4,
13.0211568133471,
0.715300723576896],
['Marine Harvest',
'MHG',
225.589705235372,
118004750966.2,
21.6878893009616,
0.440427599611273],
['Aker BP',
'AKERBP',
272.499264741749,
103712690592,
26.7636558040214,
0.722568840028356],
['Yara International',
'YAR',
333.328922090651,
99481443032.4,
86.741957363663,
0.465057636887608],
['Gjensidige Forsikring',
'GJF',
172.830508474576,
92125000000,
24.9404407385348,
0.847890127134592]]Aker BP-askjen er element nummer fem i denne listen. Om vi nå skal referere til den, så bruker vi indeks 4, siden vi starter på null.
Eksempel 4:
stocks[4]['Aker BP',
'AKERBP',
272.499264741749,
103712690592,
26.7636558040214,
0.722568840028356]Om du vil referere til siste element, bruker du indeks -1. Vil du referere til nest siste, bruker du indeks -2, og så videre:
Eksempel 5:
print(stocks[-1])
print(stocks[-2])['Gjensidige Forsikring', 'GJF', 172.830508474576, 92125000000, 24.9404407385348, 0.847890127134592]
['Yara International', 'YAR', 333.328922090651, 99481443032.4, 86.741957363663, 0.465057636887608]Du kan også referere til flere elementer som står ved siden av hverandre med en såkalt slice, eller skjære som vi kan kalle det på norsk:
Eksempel 6:
#Fra element to til og med tre:
stocks[2:4][['Telenor',
'TEL',
148.737572948101,
227115017138.4,
13.0211568133471,
0.715300723576896],
['Marine Harvest',
'MHG',
225.589705235372,
118004750966.2,
21.6878893009616,
0.440427599611273]]#Fra og med nest siste element:
stocks[-2:][['Yara International',
'YAR',
333.328922090651,
99481443032.4,
86.741957363663,
0.465057636887608],
['Gjensidige Forsikring',
'GJF',
172.830508474576,
92125000000,
24.9404407385348,
0.847890127134592]]#Til og med nest siste element:
stocks[:-1][['Equinor',
'EQNR',
167.554919090282,
376883380048.5,
6.14609823076753,
0.617893838660362],
['DNB', 'DNB', 164, 259169427140, 11.1121822724349, 0.914999939276725],
['Telenor',
'TEL',
148.737572948101,
227115017138.4,
13.0211568133471,
0.715300723576896],
['Marine Harvest',
'MHG',
225.589705235372,
118004750966.2,
21.6878893009616,
0.440427599611273],
['Aker BP',
'AKERBP',
272.499264741749,
103712690592,
26.7636558040214,
0.722568840028356],
['Yara International',
'YAR',
333.328922090651,
99481443032.4,
86.741957363663,
0.465057636887608]]Og vi kan referere til en liste inne i en liste:
Eksempel 7:
print(f"Det tredje selskapet er {stocks[2][0]}")Det tredje selskapet er TelenorDet tredje selskapet, altså Equinor, har indeks to, siden Python starter indekseringen på 0.
Det er enkelt å utvide lister, vi bruker bare +. Om vi for eksempel vil legge til selskapet ['Tomra Systems', 'TOM', 276.409619134278, 41208789715.2, 52.8996016883184, 0.454299114121939], kan vi gjøre det slik:
Eksempel 8:
tomra_systems=['Tomra Systems', 'TOM', 276.409619134278, 41208789715.2, 52.8996016883184, 0.454299114121939]
stocks=stocks+[tomra_systems]
stocks[['Equinor',
'EQNR',
167.554919090282,
376883380048.5,
6.14609823076753,
0.617893838660362],
['DNB', 'DNB', 164, 259169427140, 11.1121822724349, 0.914999939276725],
['Telenor',
'TEL',
148.737572948101,
227115017138.4,
13.0211568133471,
0.715300723576896],
['Marine Harvest',
'MHG',
225.589705235372,
118004750966.2,
21.6878893009616,
0.440427599611273],
['Aker BP',
'AKERBP',
272.499264741749,
103712690592,
26.7636558040214,
0.722568840028356],
['Yara International',
'YAR',
333.328922090651,
99481443032.4,
86.741957363663,
0.465057636887608],
['Gjensidige Forsikring',
'GJF',
172.830508474576,
92125000000,
24.9404407385348,
0.847890127134592],
['Tomra Systems',
'TOM',
276.409619134278,
41208789715.2,
52.8996016883184,
0.454299114121939]]Unngå uønsket endring av objekter
En veldig vanlig nybegynnerfeil i Python er å glemme at selv om et objekt, slik som en liste, har fått nytt navn, så er det fortsatt det samme objektet. Dette er spesielt lett å glemme når du objektet er et argument i en funksjon. Her er for eksempel en funksjon som opererer på argumentet:
Eksempel 9:
#This function removes element i it
def pop_and_print(a,i):
last_element=a.pop(-1)
print(last_element)
pop_and_print(stocks,-1)
stocks['Tomra Systems', 'TOM', 276.409619134278, 41208789715.2, 52.8996016883184, 0.454299114121939][['Equinor',
'EQNR',
167.554919090282,
376883380048.5,
6.14609823076753,
0.617893838660362],
['DNB', 'DNB', 164, 259169427140, 11.1121822724349, 0.914999939276725],
['Telenor',
'TEL',
148.737572948101,
227115017138.4,
13.0211568133471,
0.715300723576896],
['Marine Harvest',
'MHG',
225.589705235372,
118004750966.2,
21.6878893009616,
0.440427599611273],
['Aker BP',
'AKERBP',
272.499264741749,
103712690592,
26.7636558040214,
0.722568840028356],
['Yara International',
'YAR',
333.328922090651,
99481443032.4,
86.741957363663,
0.465057636887608],
['Gjensidige Forsikring',
'GJF',
172.830508474576,
92125000000,
24.9404407385348,
0.847890127134592]]Over brukes pop-metoden til listeobjektet. En “metode” er en funksjon som kan henges på et bestemt objekt. Liste-objektet har altså en metode pop, som vi kan henge på listeobjektet med et punktum. pop-metoden fjerner elementet angitt av argumentet (siste element -1 i eksemplet under), og returnerer det fjernede elementet.
Kjører du koden over mange nok ganger, vil du se at alle elementene til slutt er borte og du får feilmelding.
Av og til vil du at funksjonen skal operere på argumentet, men om det ikke er meningen at argumentet skal være endret når funksjonen er ferdigkjørt, så kan du ta en kopi inne i funksjonen. Det gjøres enklest ved å bruke typen til objektet som funksjon. Du danner da et nytt objekt av samme type. For eksempel for en liste som stocksbruker du listsom funksjon
Eksempel 10:
#This function removes element i it
def pop_and_print(a,i):
#making a copy:
a=list(a)
#doing the rest:
last_element=a.pop(-1)
print(last_element)
pop_and_print(stocks,-1)
stocks['Gjensidige Forsikring', 'GJF', 172.830508474576, 92125000000, 24.9404407385348, 0.847890127134592][['Equinor',
'EQNR',
167.554919090282,
376883380048.5,
6.14609823076753,
0.617893838660362],
['DNB', 'DNB', 164, 259169427140, 11.1121822724349, 0.914999939276725],
['Telenor',
'TEL',
148.737572948101,
227115017138.4,
13.0211568133471,
0.715300723576896],
['Marine Harvest',
'MHG',
225.589705235372,
118004750966.2,
21.6878893009616,
0.440427599611273],
['Aker BP',
'AKERBP',
272.499264741749,
103712690592,
26.7636558040214,
0.722568840028356],
['Yara International',
'YAR',
333.328922090651,
99481443032.4,
86.741957363663,
0.465057636887608],
['Gjensidige Forsikring',
'GJF',
172.830508474576,
92125000000,
24.9404407385348,
0.847890127134592]]Denne koden kan kjøres så mange ganger du vil, uten at stocks endres
Tuple
En tuple fungerer ganske likt som en liste når du skal hente noe fra den. Men i motsetning til en liste, så går det ikke an å endre på en tuple etter at den er skapt. Du kan lage en tuple enten ved å bruke den innebygde funksjonen tuple() eller ved å lage en liste med en vanlig parentes:
Eksempel 11:
a=tuple(equinor)
b=('Equinor', 'EQNR', 146.85, 315357973561)
print(type(a))
print(type(b))<class 'tuple'>
<class 'tuple'>Vi kan få tak i innholdet, men det går ikke an å endre på innholdet i en tupleetter at den er skapt:
Eksempel 12:
print(a[0])
a[0]='Statoil'EquinorTypeError: 'tuple' object does not support item assignmentTuple er mest brukt i forbindelse med funksjoner, og er ikke noe vi kommer til å bruke mye tid på i dette kurset.
Numpy
Numpy er en pakke som kan gjøre matematiske beregninger på store datasett svært effektivt. Vi starter med å importere pakken, og konvertere listen vi har brukt til en numpy-matrise kalt ndarray. En matrise er en liste der alle rader har like mangee elementer, og det er jo tilfelle med vår stocks-liste.
Vi starter med å definere en liste av liste med informasjon om aksjene:
Eksempel 13:
stocks=[
['Equinor', 'EQNR', 167.554919090282, 376883380048.5, 6.14609823076753, 0.617893838660362] ,
['DNB', 'DNB', 164, 259169427140, 11.1121822724349, 0.914999939276725] ,
['Telenor', 'TEL', 148.737572948101, 227115017138.4, 13.0211568133471, 0.715300723576896] ,
['Marine Harvest', 'MHG', 225.589705235372, 118004750966.2, 21.6878893009616, 0.440427599611273] ,
['Aker BP', 'AKERBP', 272.499264741749, 103712690592, 26.7636558040214, 0.722568840028356] ,
['Yara International', 'YAR', 333.328922090651, 99481443032.4, 86.741957363663, 0.465057636887608] ,
['Gjensidige Forsikring', 'GJF', 172.830508474576, 92125000000, 24.9404407385348, 0.847890127134592] ,
['Orkla', 'ORK', 86.5857852597003, 89087299091.2, 26.5615083754323, 0.350968405416214] ,
['Norsk Hydro', 'NHY', 31.4389402413895, 67532103728.64, 15.6215830970715, 0.439195576287418] ,
['SalMar', 'SALM', 449.3, 50905689550.7, 14.222545257898, 0.396134627028104] ,
['Tomra Systems', 'TOM', 276.409619134278, 41208789715.2, 52.8996016883184, 0.454299114121939] ,
['Aker', 'AKER', 514.200494811093, 40393931997, 43.4343354806452, 0.548092886866901] ,
]Som du ser, så består listen av tolv rader og fire kolonner. Dette er altså en 12x6-matrise. Den kan enkelt konverteres til en numpy-matrise med funksjonen np.array() slik som her:
Eksempel 14:
import numpy as np
stocks_np=np.array(stocks)Listen er nå lagret som en numpy 12x6-matrise i objektet stocks_np. Vi kan imidlertid ikke utføre noen matematiske beregninger slik denne matrisen står, fordi alle tall er i tekstformat. Som vi har sett tidligere går det bare an å regne med float, int og bool. At det er tekst ser vi ved at det er enkle anførselstegn ' rundt alle elementene.
Heldigvis er det veldig enkelt å hente ut informasjon fra numpy-matriser, fordi mulighetene til å skjære utsnitt er langt større enn for vanlige lister. Numpy-lister kan nemlig skjæres i flere dimensjoner.
I motsetning til vanlige lister, kan vi for eksempel velge ut kolonner. I en liste av lister velger du, som vi har sett, rad 2 og kolonne 0 med stocks[2][0]. Med numpy-matriser separerer du de to indeksene med et komma, stocks[2,0].
Men enda viktigere, du kan velge alle elementer ved å sette inn kolon : i stedet for tall. Dermed kan du velge hele kolonne 0 med stocks_np[:,0].
Her er vi mest interessert i de to siste kolonnene. Det er disse som inneholder tall. For å plukke ut disse velger vi alle radene (:) og alle kolonnene fra og med kolonne 2 (2:). Da får vi
Eksempel 15:
stocks_np[:,2:]array([['167.554919090282', '376883380048.5', '6.14609823076753',
'0.617893838660362'],
['164', '259169427140', '11.1121822724349', '0.914999939276725'],
['148.737572948101', '227115017138.4', '13.0211568133471',
'0.715300723576896'],
['225.589705235372', '118004750966.2', '21.6878893009616',
'0.440427599611273'],
['272.499264741749', '103712690592', '26.7636558040214',
'0.722568840028356'],
['333.328922090651', '99481443032.4', '86.741957363663',
'0.465057636887608'],
['172.830508474576', '92125000000', '24.9404407385348',
'0.847890127134592'],
['86.5857852597003', '89087299091.2', '26.5615083754323',
'0.350968405416214'],
['31.4389402413895', '67532103728.64', '15.6215830970715',
'0.439195576287418'],
['449.3', '50905689550.7', '14.222545257898', '0.396134627028104'],
['276.409619134278', '41208789715.2', '52.8996016883184',
'0.454299114121939'],
['514.200494811093', '40393931997', '43.4343354806452',
'0.548092886866901']], dtype='<U32')Sist i matrisen over, står det dtype='<U21'. Det betyr at dette er tekstrenger på 21 eller færre tegn. Vi må imidlertid ha dette over i tallformat for å kunne jobbe med det. Det gjør vi slik:
Eksempel 16:
stocks_numbers=np.array(stocks_np[:,2:],dtype=float)
stocks_numbersarray([[1.67554919e+02, 3.76883380e+11, 6.14609823e+00, 6.17893839e-01],
[1.64000000e+02, 2.59169427e+11, 1.11121823e+01, 9.14999939e-01],
[1.48737573e+02, 2.27115017e+11, 1.30211568e+01, 7.15300724e-01],
[2.25589705e+02, 1.18004751e+11, 2.16878893e+01, 4.40427600e-01],
[2.72499265e+02, 1.03712691e+11, 2.67636558e+01, 7.22568840e-01],
[3.33328922e+02, 9.94814430e+10, 8.67419574e+01, 4.65057637e-01],
[1.72830508e+02, 9.21250000e+10, 2.49404407e+01, 8.47890127e-01],
[8.65857853e+01, 8.90872991e+10, 2.65615084e+01, 3.50968405e-01],
[3.14389402e+01, 6.75321037e+10, 1.56215831e+01, 4.39195576e-01],
[4.49300000e+02, 5.09056896e+10, 1.42225453e+01, 3.96134627e-01],
[2.76409619e+02, 4.12087897e+10, 5.28996017e+01, 4.54299114e-01],
[5.14200495e+02, 4.03939320e+10, 4.34343355e+01, 5.48092887e-01]])Når vi konverterte listen til en ndarray, så brukte vi altså funksjonen np.array(), slik som i Eksempel 14. Men denne gangen legger vi til det valgfrie argument dtype=float for å eksplisitt gi beskjed om at vi ønsker strengene konvertert til flyttal.
Nå kan vi begynne å bruke tallene. For eksempel kan vi se grafisk om det er en sammenheng mellom gjeldsgrad og pris-inntjeningstraten (PE). Dette er de to siste kolonnene i datamatrisen:
Eksempel 17:
from matplotlib import pyplot as plt
fig,ax=plt.subplots()
ax.set_ylabel('PE')
ax.set_xlabel('gjeldsrate')
ax.scatter(stocks_numbers[:,-1], stocks_numbers[:,-2])<matplotlib.collections.PathCollection at 0x29f7edd0b50>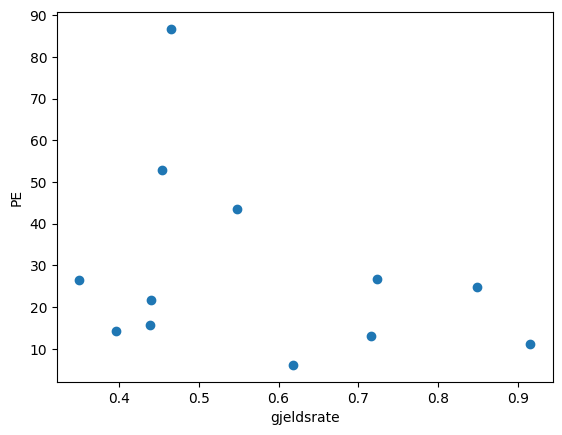
Ser du en sammenheng?
Det er også enkelt å regne med Numpy. Vi kan bruke alle de vanlige regneartene med numpy-matriser:
a=np.array([1,5,6,3])
b=np.array([23,15,2,10])
print(a+b)
print(a-b)
print(a*b)
print(a/b)
print(a**3)
print(a**0.5)#Kvadratroten[24 20 8 13]
[-22 -10 4 -7]
[23 75 12 30]
[0.04347826 0.33333333 3. 0.3 ]
[ 1 125 216 27]
[1. 2.23606798 2.44948974 1.73205081]Oppslag
Et oppslag, eller dictionary har symbol dict i Python. Dette er en datastruktur der hvert element ikke identifiseres med hvor det er plassert, men med et nøkkelord (key). Å bruke oppslag i stedet for lister gjør ofte koden mer lesbar. Det finnes to måter å lage oppslag på; enten ved å bruke funksjonen dict():
Eksempel 18:
a=dict()
a['gjeldsrate']=stocks_numbers[:,-1]
a['PE']=stocks_numbers[:,-2]
print(type(a))<class 'dict'>Som vi ser, blir dette et objekt av type dict. Alternativt kan vi definere elementer inne i en krølleparentes på formen {nøkkel: objekt}, slik som dette:
b={
'gjeldsrate':stocks_numbers[:,-1],
'PE':stocks_numbers[:,-2],
}
print(type(b))<class 'dict'>Her er det altså to elementer med nøkler 'gjeldsrate' og 'PE', og tilhørende objekter fra stocks_numbers.
Vi legger merke til at dette også er en objekt av type dict. Med oppslag blir det enklere å bruke variablene, siden vi kan referere til dem med navn i stedet for indeks. Her er plottet i Eksempel 17 gjort med oppslag:
Eksempel 19:
plt.ylabel('PE')
plt.xlabel('gjeldsrate')
plt.scatter(a['gjeldsrate'], a['PE'])<matplotlib.collections.PathCollection at 0x29f69d5f250>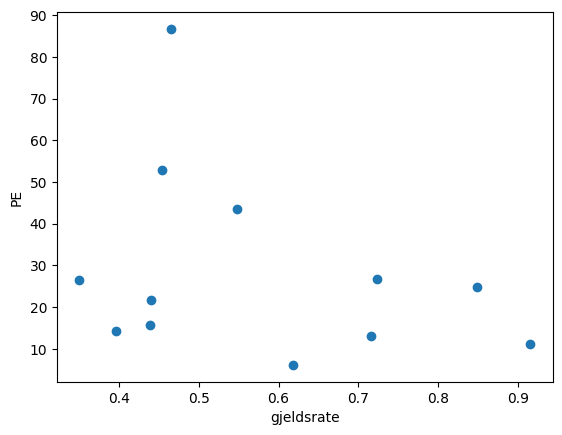
Når du først har laget en dict, er det enkelt å legge til nye elementer. Det gjør du enkelt ved å bruke en nøkkel som ikke finnes, for eksempel 'Pris', og dette elementet lik ønsket objekt:
Eksempel 20:
a['Pris']=stocks_numbers[:,0]
plt.ylabel('Pris')
plt.xlabel('gjeldsrate')
plt.scatter(a['gjeldsrate'], a['Pris'])<matplotlib.collections.PathCollection at 0x29f7f6cf250>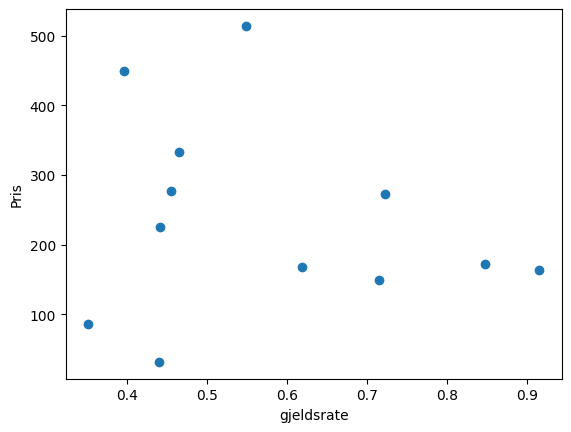
dict-objektet er helt sentralt i selve byggeklossene til Python. Alle variabler du lager er faktisk elementer i to dict som du kan få frem med funksjonene locals() og globals(), som kaller de lokalt og globalt definerte variablene i miljøet du befinner deg. Dette eksemplet viser at objektet stocks som vi har definert i Eksempel 13, er identisk med elementet 'stocks' i locals().
Eksempel 21:
locals()['stocks']==stocksTrueVi ser at disse objektene egentlig er det samme, ved at den logiske testen om disse er like, returnerer sann (True).
Oppgaver
Det er enkelt å konvertere en pandas dataramme til numpy. Vi skal bruke skolegangeksemplet fra forelesning “3 - matplotlib”. Vi henter inn dataene og konverterer dem til numpy slik:
import numpy as np
import pandas as pd
df=pd.read_csv('./data/schooling-gdp.csv')
schooling=np.array(df)
schoolingarray([['Norway', ' NOR', 73262.68, 11.65, 4886000],
['Kuwait', ' KWT', 67029.523, 6.39, 2992000],
['Luxembourg', ' LUX', 57882.809, 11.33, 508000],
['Switzerland', ' CHE', 55688.02, 12.92, 7809000],
['United States', ' USA', 49500.629, 13.24, 309011008],
['Ireland', ' IRL', 47823.504, 12.45, 4554000],
['Australia', ' AUS', 44854.902, 11.69, 22155000],
['Netherlands', ' NLD', 44004.145, 11.71, 16683000],
['Denmark', ' DNK', 43416.223, 11.97, 5555000],
['Hong Kong', ' HKG', 41687.949, 12.2, 6966000],
['Germany', ' DEU', 40627.23, 12.58, 80827000],
['Austria', ' AUT', 40489.809, 10.13, 8410000],
['Sweden', ' SWE', 40421.906, 11.95, 9390000],
['Canada', ' CAN', 40269.031, 12.74, 34148000],
['Finland', ' FIN', 38394.059, 10.71, 5366000],
['Belgium', ' BEL', 38177.945, 11.29, 10939000],
['Iceland', ' ISL', 37729.016, 11.48, 320000],
['Taiwan', ' TWN', 37188.895, 11.96, 23188000],
['Japan', ' JPN', 36595.633, 12.44, 128542000],
['France', ' FRA', 35786.16, 11.34, 62880000],
['United Kingdom', ' GBR', 34810.281, 12.46, 63460000],
['Italy', ' ITA', 34727.676, 10.71, 59325000],
['Spain', ' ESP', 31610.98, 10.75, 46931000],
['South Korea', ' KOR', 31589.705, 12.96, 49546000],
['New Zealand', ' NZL', 30867.053, 11.12, 4370000],
['Cyprus', ' CYP', 28046.375, 11.76, 1113000],
['Trinidad and Tobago', ' TTO', 27510.236, 10.96, 1328000],
['Czechia', ' CZE', 26129.568, 12.8, 10537000],
['Greece', ' GRC', 25815.799, 11.36, 10888000],
['Portugal', ' PRT', 25788.273, 8.71, 10596000],
['Malta', ' MLT', 22983.451, 11.06, 414000],
['Russia', ' RUS', 21754.066, 12.02, 143479008],
['Poland', ' POL', 21006.027, 11.62, 38330000],
['Hungary', ' HUN', 20477.799, 11.98, 9927000],
['Chile', ' CHL', 18092.941, 10.35, 17063000],
['Turkey', ' TUR', 17930.68, 7.44, 72327000],
['Malaysia', ' MYS', 17913.164, 10.89, 28208000],
['Iran', ' IRN', 17328.459, 9.15, 73763000],
['Romania', ' ROU', 16775.609, 11.08, 20472000],
['Venezuela', ' VEN', 16357.737, 8.78, 28440000],
['Argentina', ' ARG', 15841.659, 9.71, 40896000],
['Uruguay', ' URY', 15783.405, 8.61, 3359000],
['Mauritius', ' MUS', 15178.326, 9.44, 1248000],
['Panama', ' PAN', 15055.237, 9.72, 3643000],
['Bulgaria', ' BGR', 14906.785, 11.07, 7425000],
['Mexico', ' MEX', 14507.013, 9.18, 114093000],
['Barbados', ' BRB', 13995.613, 9.57, 282000],
['Brazil', ' BRA', 13541.462, 8.17, 195714000],
['Algeria', ' DZA', 12590.226, 7.0, 35977000],
['Thailand', ' THA', 12496.244, 8.47, 67195000],
['Serbia', ' SRB', 12453.482, 11.52, 8991000],
['Costa Rica', ' CRI', 12106.992, 8.43, 4577000],
['Dominican Republic', ' DOM', 11500.132, 8.12, 9695000],
['South Africa', ' ZAF', 11388.641, 9.89, 51217000],
['Tunisia', ' TUN', 10647.835, 8.0, 10635000],
['Colombia', ' COL', 10636.5, 9.35, 45223000],
['Albania', ' ALB', 9544.7402, 10.44, 2948000],
['Jordan', ' JOR', 9351.3877, 10.0, 7262000],
['Iraq', ' IRQ', 9344.5439, 7.43, 29742000],
['China', ' CHN', 9337.29, 8.25, 1368811008],
['Peru', ' PER', 9262.1641, 9.28, 29028000],
['Egypt', ' EGY', 9148.8398, 7.44, 82761000],
['Ecuador', ' ECU', 9129.1367, 8.02, 15011000],
['Sri Lanka', ' LKA', 8390.4297, 10.67, 20262000],
['Indonesia', ' IDN', 7365.4385, 8.02, 241834000],
['Belize', ' BLZ', 7145.9521, 9.63, 322000],
['Eswatini', ' SWZ', 7042.5239, 5.33, 1065000],
['Fiji', ' FJI', 6902.0688, 10.35, 860000],
['Paraguay', ' PRY', 6825.2051, 7.99, 6248000],
['Jamaica', ' JAM', 6675.1768, 10.33, 2810000],
['Morocco', ' MAR', 6421.9375, 5.27, 32343000],
['Guatemala', ' GTM', 6359.2627, 5.21, 14630000],
['El Salvador', ' SLV', 6096.9585, 8.06, 6184000],
['Syria', ' SYR', 5700.3291, 7.07, 21363000],
['Philippines', ' PHL', 5391.2339, 8.65, 93967000],
['Bolivia', ' BOL', 4806.6094, 8.57, 10049000],
['Yemen', ' YEM', 4553.5571, 3.84, 23155000],
['India', ' IND', 4357.0596, 6.59, 1234280960],
['Pakistan', ' PAK', 4171.4165, 5.19, 179424992],
['Nicaragua', ' NIC', 3992.762, 6.82, 5824000],
['Ghana', ' GHA', 3931.2917, 7.66, 24780000],
['Honduras', ' HND', 3789.9104, 6.6, 8317000],
['Sudan', ' SDN', 3608.7856, 3.49, 34545000],
['Myanmar', ' MMR', 3422.2415, 5.11, 50601000],
['Zambia', ' ZMB', 2870.8872, 7.4, 13606000],
['Senegal', ' SEN', 2741.1213, 3.11, 12678000],
['Cameroon', ' CMR', 2684.9727, 6.41, 20341000],
['Gambia', ' GMB', 2681.8586, 3.92, 1793000],
['Kenya', ' KEN', 2484.0349, 6.47, 42031000],
["Cote d'Ivoire", ' CIV', 2452.6096, 4.93, 20533000],
['Lesotho', ' LSO', 2432.7976, 6.08, 1996000],
['Bangladesh', ' BGD', 2411.1021, 6.22, 147575008],
['Cambodia', ' KHM', 2330.1272, 4.94, 14312000],
['Nepal', ' NPL', 1996.1962, 4.44, 27013000],
['Benin', ' BEN', 1919.9968, 4.57, 9199000],
['Mali', ' MLI', 1873.281, 2.14, 15049000],
['Uganda', ' UGA', 1723.5942, 5.87, 32428000],
['Haiti', ' HTI', 1650.2697, 5.17, 9949000],
['Zimbabwe', ' ZWE', 1479.0305, 7.86, 12698000],
['Togo', ' TGO', 1222.8151, 6.09, 6422000],
['Sierra Leone', ' SLE', 1161.8798, 4.28, 6416000],
['Malawi', ' MWI', 972.04572, 5.01, 14540000],
['Mozambique', ' MOZ', 969.23077, 2.03, 23532000],
['Niger', ' NER', 845.86932, 1.95, 16464000],
['Liberia', ' LBR', 786.67023, 4.35, 3891000],
['Democratic Republic of Congo', ' COD', 634.97137, 3.79,
64564000]], dtype=object)- Bytt ut navnet til “Ireland” med “Republic of Ireland” og “United States” med “United States of America”
schooling[5][0]="Republic of Ireland"
schooling[4][0]="United States of America"
schooling[:7]array([['Norway', ' NOR', 73262.68, 11.65, 4886000],
['Kuwait', ' KWT', 67029.523, 6.39, 2992000],
['Luxembourg', ' LUX', 57882.809, 11.33, 508000],
['Switzerland', ' CHE', 55688.02, 12.92, 7809000],
['United States of America', ' USA', 49500.629, 13.24, 309011008],
['Republic of Ireland', ' IRL', 47823.504, 12.45, 4554000],
['Australia', ' AUS', 44854.902, 11.69, 22155000]], dtype=object)- Print data for “Luxembourg”
print(schooling[2])['Luxembourg' ' LUX' 57882.809 11.33 508000]- Print data for “Liberia” ved å referere til nest siste element.
schooling[-2]array(['Liberia', ' LBR', 786.67023, 4.35, 3891000], dtype=object)- Print BNP per capita for de tre siste elementene i
schooling(ligger i kolonne med indeks 2)
np.array(schooling)[len(schooling)-3:,2]array([845.86932, 786.67023, 634.97137], dtype=object)- Print BNP per capita for de tre siste elementene i
schoolingmen hent kolonnen ved å refere til tredje siste kolonne.
np.array(schooling)[-3:,2]array([845.86932, 786.67023, 634.97137], dtype=object)- Plukk ut de tre siste kolonnene i
schooling, som representerer BNP per capita, skolegang og befolkning, og konverter dem til datatypefloat.
schooling_float = np.array(np.array(schooling)[:,-3:],dtype=float)- Lag et oppslag (dictionary) med de tre siste kolonnene og passende navn som nøkler. Kall det
schooling_dict.
schooling_dict = {'gdp_cap': schooling_float[:,0], 'schooling': schooling_float[:,1], 'pop': schooling_float[:,2]}- Lag en ny variabel i oppslaget med navn “Total schooling” som er produktet av skolegang og befolkning.
schooling_dict["Total schooling"] = schooling_dict["schooling"]*schooling_dict["pop"]- Lag en ny variabel “Total GDP” som er produktet av BNP per capita og befolkning.
schooling_dict["Total GDP"] = schooling_dict["gdp_cap"]*schooling_dict["pop"]- Lag et scatterplot med de to variablene du nettopp lagde.
plt.scatter(schooling_dict["Total schooling"],schooling_dict["Total GDP"])<matplotlib.collections.PathCollection at 0x29f1d704790>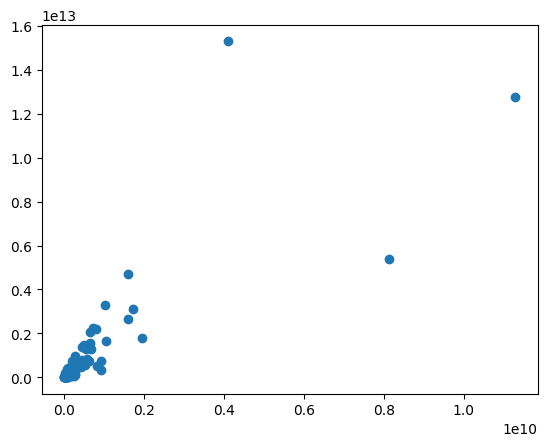
- Lag plottet over, men konverter variablene med np.log()
plt.scatter(np.log(schooling_dict["Total schooling"]),np.log(schooling_dict["Total GDP"]))<matplotlib.collections.PathCollection at 0x29f1d878c10>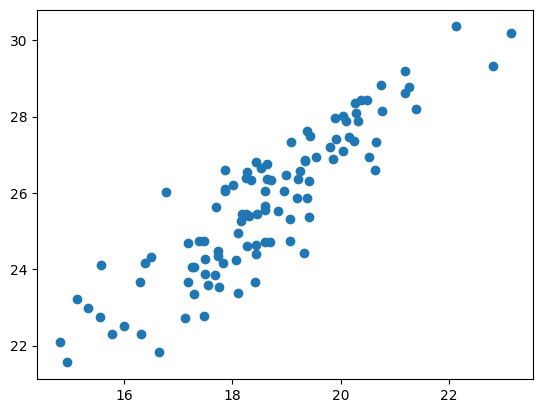
- Lag en ny variabel “GDP per schooling” som er BNP per capita delt på skolegang.
schooling_dict["GDP per schooling"] = schooling_dict["gdp_cap"]/schooling_dict["schooling"]- Lag et liggende stolpediagram med navn på land og “GDP per schooling”. Du bruker da funksjonen
plt.barhpå denne måten:
plt.barh(names,values)Hvor names er en liste med navnene og values er de tilhørende verdiene.
plt.barh(schooling[:,0],schooling_dict["GDP per schooling"])<BarContainer object of 106 artists>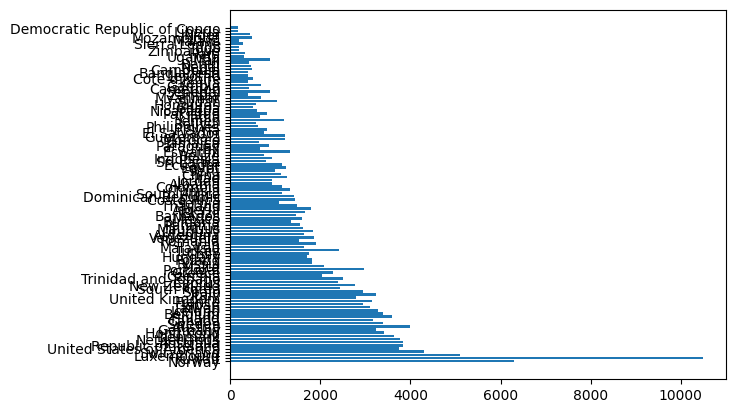
- Dette blir ikke pent. Velg kun de 20 første landene, og forsøk på nytt.
ncount = 20
plt.barh(schooling[:,0][:ncount],schooling_dict["GDP per schooling"][:ncount])<BarContainer object of 20 artists>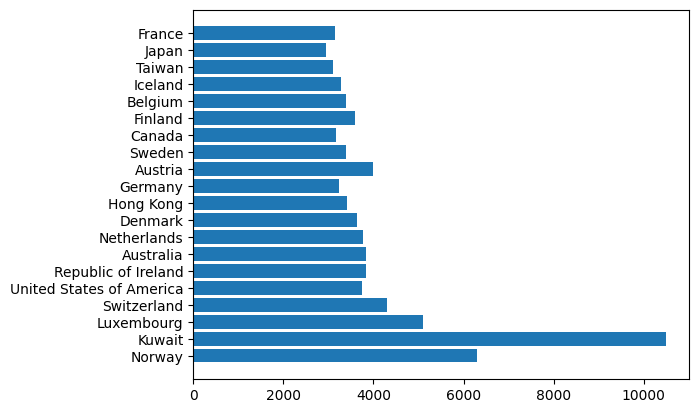
- med
argsortfår du rangeringen til etter en sortering. Her er rangeringen for “GDP per schooling”
schooling_dict["GDP per schooling"].argsort()[::-1]array([ 1, 0, 2, 3, 11, 5, 6, 7, 4, 8, 14, 9, 12,
15, 16, 21, 10, 13, 19, 17, 29, 18, 22, 20, 24, 26,
23, 35, 25, 28, 30, 27, 37, 39, 41, 31, 32, 48, 34,
33, 47, 36, 40, 42, 45, 43, 38, 49, 46, 51, 52, 44,
54, 66, 58, 61, 71, 70, 76, 53, 62, 55, 59, 50, 82,
60, 57, 64, 56, 85, 95, 68, 73, 78, 63, 72, 65, 87,
83, 67, 77, 69, 74, 79, 81, 75, 80, 89, 102, 92, 93,
103, 94, 86, 90, 84, 91, 88, 97, 96, 100, 99, 101, 98,
104, 105], dtype=int64)[::-1] til slutt sørger for å reversere sorteringen. Legg referansen til soreringen inn i variabelen sorted, og lag diagrammet på nytt med sorterte verdier. Om du har en numpy-liste a, kan du velge de sorterte verdiene med a[sorted]
Lag
et nytt diagram med alle landene og
et diagram med de 20 øverste.
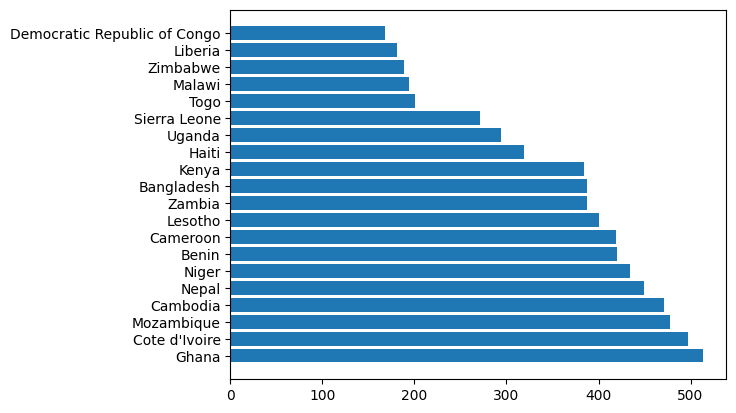
et diagram med de 20 nederste
sorted = schooling_dict["GDP per schooling"].argsort()[::-1]
plt.barh(schooling[:,0][sorted],schooling_dict["GDP per schooling"][sorted])<BarContainer object of 106 artists>
plt.barh(schooling[:,0][sorted][:ncount],schooling_dict["GDP per schooling"][sorted][:ncount])<BarContainer object of 20 artists>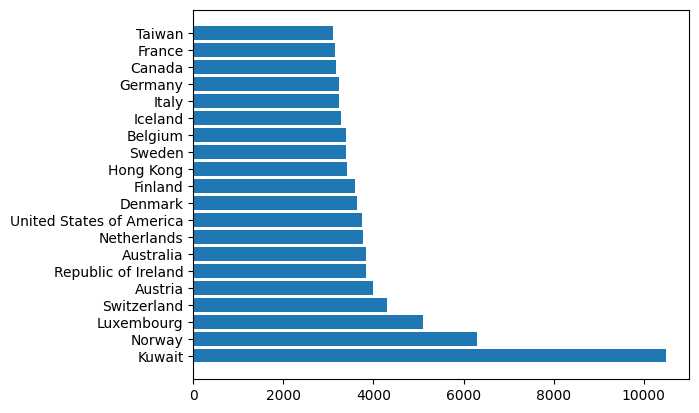
plt.barh(schooling[:,0][sorted][-ncount:],schooling_dict["GDP per schooling"][sorted][-ncount:])<BarContainer object of 20 artists>