if False:
print("Hei")
else:
print("Hå")Hå6 - pandas, filtrering, logikk og betingelser
Noe av det vi gjør oftest når vi programmerer er å teste om en betingelse er sann eller usann. Når testen er utført, kan programmet velge riktig vei å gå i fortsettelsen. Slik testing kalles “logikk”. Vi har allerede i innledningen vært inne på variabeltypen som avgjør om en test er sann eller usann, typen bool.
Sann eller usann (True og False) brukes som oftest sammen med en if-betingelse, slik som dette:
if False:
print("Hei")
else:
print("Hå")HåVanligvis vil if-setningen inneholde en test som ikke er helt åpenbar, og som avhenger av input i en funksjon eller en variabel som er definert et annet sted i koden. Her er et eksempel på det første:
import numpy as np
def did_I_win(s0,s1):
if s1>s0:
return "won!"
else:
return "lost"
PricePaid=100
StockPriceToday=int(np.random.rand()*200)
print(
f"Bought for: {PricePaid}\n"
f"Worth today: {StockPriceToday}\n"
f"You {did_I_win(PricePaid,StockPriceToday)}"
)Bought for: 100
Worth today: 171
You won!Ofte vil du ønske å sammenligne ulike datasett, for eksempel to numpy-rekker. Dersom du skal ha en if-betingelse, må du imidlertid huske på at for å få ett svar på en sammenligning mellom to numpy-rekker, så må du angi på hvilken måte de skal sammenlignes. I utgangspunktet vil en slik sammenligning bare gi resultatet fra en sammenligning av hvert element i de to rekkene. Resultatet av sammenligningen er altså ikke en bolsk verdi (bool) men en ny rekke. En slik sammenligning vil derfor føre til en feil:
a=np.array([1,2,3])
b=np.array([3,2,1])
print(a>b)
if a>b:
print('a was bigger than b')[False False True]ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()I stedet må vi angi hvordan den elementvise sammenligningen skal sammenfattes i et sant/usant-resultat. Vi kan da velge mellom å kreve at alle elementene er sanne med numpyfunksjonen all(), eller at minst ett av elementene er sanne medany().
if np.any(a>b):
print('There were elements in a where the corresponding element in b was smaller')
a=np.array([101,102,103])
if np.all(a>b):
print('All elements in a was bigger than the corresponding element in b')There were elements in a where the corresponding element in b was smaller
All elements in a was bigger than the corresponding element in bOfte vil du ha bruk for å bruke flere vilkår for testen, der du enten krever at alle må være sanne, eller at det holder at én er sann, eller en kombinasjon. Det oppnår vi med and og or.
Et annet nyttig nøkkelord for logiske tester er in. Dette brukes på alt fra å finne ut om et objekt er i en liste eller annen datastruktur, til om en delstreng er i en streng. Her er et eksempel som bruker alle disse nøkkelordene i if og elif-setninger:
animal='lion'
cats=['lion','tiger','puma','lynx']
mammals=['human','bear','cat','whale','mouse']+cats
if (animal in cats) and (animal in mammals):
print(f"{animal} is a cat and a mammal")
elif (not animal in cats) and (animal in mammals):
print(f"{animal} is not a cat, but it is a mammal")
elif (animal in cats) and (not animal in mammals):
print(f"{animal} is a cat, but not a mammal")
else:
print(f"{animal} is neither a cat nor a mammal")lion is a cat and a mammalLegg merke til elif over. De er if-setninger som er knyttet til if-setningen over. Koden til en elif-setning kjøres dersom hverken if-setningen eller noen elif-setninger over har blitt tilfredsstilt.
Vanligvis vil slike tester ligge inne i kode der det ikke er helt åpenbart hva variabelen du tester er. Dette er illustrert i eksemplet under, der variabelen bestemmes av innholdet i datasettet “schooling-gdp.csv”. Vi starter med å hente inn datasettet og plotte BNP per capita mot Utdanning:
import pandas as pd
df=pd.read_csv('./data/schooling-gdp.csv')
df.plot.scatter('BNP_per_capita','Utdanning')<AxesSubplot: xlabel='BNP_per_capita', ylabel='Utdanning'>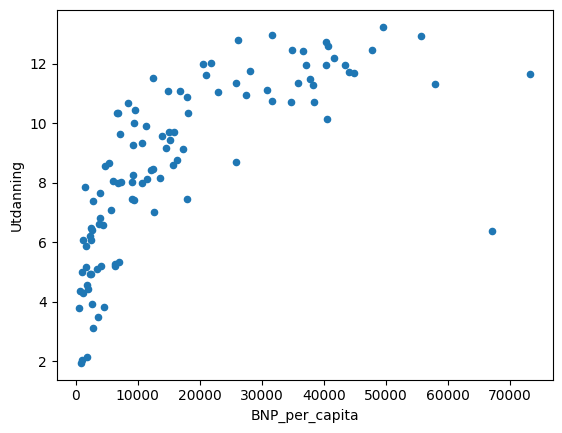
Vi ser at sammenhengen virker mer usikker for når utdanningsnivået og BNP per capita er høyt. Vi kan derfor bruke en if-setning til å kun ta med land med høyt BNP per capita eller høyt utdanningsnivå. Vi ønsker også å kun se på andre land en Norge. Da kan vi for eksempel kjøre denne koden:
index_list=[]
for index, (country,code,gdp_cap,edu,pop) in df.iterrows():
if (gdp_cap>20000 and country!='Norway') or edu>10:
index_list.append(index)
df_filtered=df[df.index.isin(index_list)]
df_filtered.plot.scatter('BNP_per_capita','Utdanning')<AxesSubplot: xlabel='BNP_per_capita', ylabel='Utdanning'>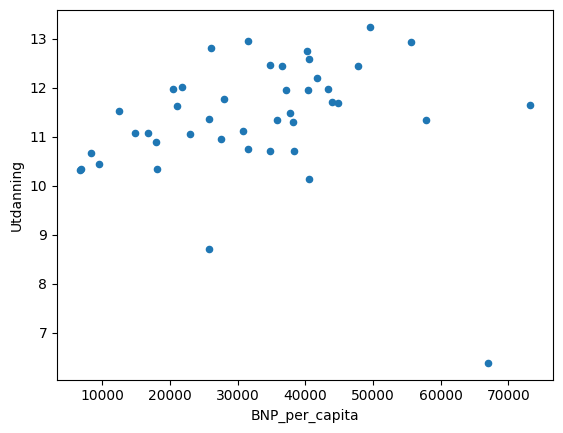
index_list=[]
for index, (country,code,gdp_cap,edu,pop) in df.iterrows():
if (gdp_cap>20000 and country!='Norway') :
index_list.append(index)
df_filtered=df[df.index.isin(index_list)]
df_filtered.plot.scatter('BNP_per_capita','Utdanning')<AxesSubplot: xlabel='BNP_per_capita', ylabel='Utdanning'>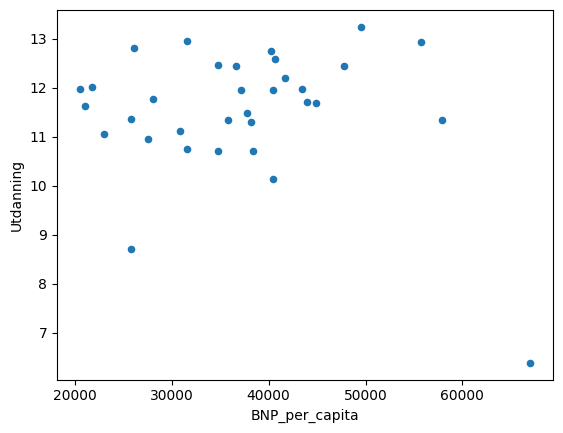
Her lager vi en liste, og legger til indeksen til hvert element i datarammen df som skal inkluderes. Vi velger så ut radene i datarammen med disse indeksene med dataframe-funksjonen isin(). Funksjonens navn kommer fra is in, så den tester altså om index_list er i datarammen df. Som vi ser, ser det ut til å være er det liten sammenheng mellom BNP per capita og utdanningsnivå for disse observasjonene.
I eksemplet over leser Pandas dataene fra en fiil, men Pandas kan også hente data direkte fra en database på nettet. Vi skal først se hvordan vi kan hente data fra titlon.uit.no. Dette er en database som inneholder informasjon om aksjer, derviater og obligasjoner handlet på Oslo Børs Euronext.
Det første vi må gjøre er å hente en pakke som kan kommunisere med serveren. Vi skal bruke pymysql. Den er i utgangspunktet ikke installert her på uit’s jupyter-server, så det må vi gjøre selv. Det gjør du slik:
Åpne konsollen og skriv pip install pymysql
For å hente data gjør du følgende:
På https://titlon.uit.no/ ligger det børsinformasjon fra Oslo Børs. For å hente data fra Titlon gjør du følgende:
LES INSTRUKSJONENE OVER! KODEN UNDER KAN IKKE KJØRES UTEN VIDERE.
import pandas as pd
#Query script for MySQL client
import pymysql
con = pymysql.connect(host='titlon.uit.no',
user="<brukernavn>",
password="Pw84hYehUu6V7sjf1r5aP",
database='OSE')
crsr=con.cursor()
crsr.execute("""
SELECT * FROM `OSE`.`equity`
WHERE (`ISIN` = 'NO0010279474')
AND year(`Date`) >= 2000
ORDER BY `Name`,`Date`
""")
r=crsr.fetchall()
df=pd.DataFrame(list(r), columns=[i[0] for i in crsr.description])
df
| Date | SecurityId | CompanyId | Symbol | ISIN | Name | BestBidPrice | BestAskPrice | Open | High | ... | lnDeltaOBX | NOWA_DayLnrate | bills_3month_Lnrate | Sector | IN_OSEBX | Equity | Debt | Earnings | debt_ratio | PE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2007-06-22 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 13.40 | 13.50 | 13.50 | 13.50 | ... | 0.000000 | 0.000215 | 0.000198 | Information Technology | 0 | 9915000.0 | 13167000.0 | -19778000.0 | 0.570445 | -9.05332 |
| 1 | 2007-06-25 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 12.75 | 13.15 | 13.50 | 13.50 | ... | -0.004561 | 0.000214 | 0.000199 | Information Technology | 0 | 9915000.0 | 13167000.0 | -19778000.0 | 0.570445 | -8.81860 |
| 2 | 2007-06-27 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 12.75 | 13.50 | 13.00 | 13.00 | ... | -0.015125 | 0.000213 | 0.000199 | Information Technology | 0 | 9915000.0 | 13167000.0 | -19778000.0 | 0.570445 | -8.71801 |
| 3 | 2007-06-28 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 12.50 | 13.00 | 13.00 | 13.00 | ... | 0.025671 | 0.000213 | 0.000202 | Information Technology | 0 | 9915000.0 | 13167000.0 | -19778000.0 | 0.570445 | -8.71801 |
| 4 | 2007-07-03 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 12.50 | 13.00 | 13.00 | 13.00 | ... | 0.002780 | 0.000213 | 0.000203 | Information Technology | 0 | 9915000.0 | 13167000.0 | -19778000.0 | 0.570445 | -8.71801 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 803 | 2013-06-21 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 1.70 | 2.00 | 1.81 | 1.81 | ... | 0.000669 | 0.000074 | 0.000066 | Information Technology | 0 | 5498000.0 | 60706000.0 | -20093000.0 | 0.916954 | -2.19938 |
| 804 | 2013-06-24 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 1.82 | 1.94 | 1.94 | 1.94 | ... | -0.029773 | 0.000074 | 0.000066 | Information Technology | 0 | 5498000.0 | 60706000.0 | -20093000.0 | 0.916954 | -2.50989 |
| 805 | 2013-06-25 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 2.00 | 2.05 | 1.94 | 2.00 | ... | 0.017821 | 0.000072 | 0.000067 | Information Technology | 0 | 5498000.0 | 60706000.0 | -20093000.0 | 0.916954 | -2.58751 |
| 806 | 2013-06-26 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 1.95 | 2.05 | 2.00 | 2.05 | ... | 0.010697 | 0.000072 | 0.000067 | Information Technology | 0 | 5498000.0 | 60706000.0 | -20093000.0 | 0.916954 | -2.58751 |
| 807 | 2013-06-27 | 66992 | 8380 | TFSO | NO0010279474 | 24Seven Technology Group | 1.80 | 2.00 | 1.90 | 2.00 | ... | -0.001409 | 0.000072 | 0.000067 | Information Technology | 0 | 5498000.0 | 60706000.0 | -20093000.0 | 0.916954 | -2.58751 |
808 rows × 53 columns
Koden leser inn dataene til en pandas dataframe, eller dataramme. Denne er kalt df her. Om vi ser nærmere på koden, så ser vi at den gjør følgende:
lager et objekt con som representerer forbindelsen med databasen. Denne lages ved å bruke connect()-funksjonen til pymysql, som er en pakke for å hente data fra MySQL-databaser. Input er navn på server, brukernavn, passord (automatisk generert) og navn på database.
lager en streng sql med kommandoen til databasen, i SQL-språk
lager en dataframe som kalles df ved å bruke read_sql_query-funksjonen i pandas
Før vi fortsetter er det kanskje greit å forklare hva SQL er. SQL er et språk laget spesifikt for å hente ut data fra dataabaser. Nesten alle databaser er SQL-basert. Syntaksen kan virke litt knotete, men kan være lurt å lære seg dette språket. En god SQL-spørring kan spare deg for mye programmering senere. Dette er imidlertid ikke et kurs i SQL, så vi går ikke nærmere inn på denne syntaksen her.
I tabellen vi henter, over, mangler endel variabler fordi det ikke er plass. For å se navnet på alle variablene kan du bruke keys()-funksjonen til datarammen:
df.keys()Index(['Date', 'SecurityId', 'CompanyId', 'Symbol', 'ISIN', 'Name',
'BestBidPrice', 'BestAskPrice', 'Open', 'High', 'Low', 'Close',
'OfficialNumberOfTrades', 'OfficialVolume', 'UnofficialNumberOfTrades',
'UnofficialVolume', 'VolumeWeightedAveragePrice', 'Price',
'AdjustedPrice', 'Dividends', 'LDividends', 'CorpAdj', 'DividendAdj',
'Currency', 'Description', 'CountryCode', 'SumAnnualDividends',
'NumberOfShares', 'CompanyOwnedShares', 'OutstandingShares', 'Exchange',
'NOKPerForex', 'mktcap', 'OSEBXmktshare_prevmnth',
'OSEBXAlpha_prevmnth', 'OSEBXBeta_prevmnth', 'SMB', 'HML', 'LIQ', 'MOM',
'DividendPriceRatio', 'lnDeltaP', 'lnDeltaOSEBX', 'lnDeltaOBX',
'NOWA_DayLnrate', 'bills_3month_Lnrate', 'Sector', 'IN_OSEBX', 'Equity',
'Debt', 'Earnings', 'debt_ratio', 'PE'],
dtype='object')En dataframe ligner litt på en oppslagsliste. Du henter frem variabelen du vil bruke ved hjelp av hakeparenteser. I Titlondatabasen er avkastningen lnDeltaP, så la oss ta en kikk på på den:
df['lnDeltaP']0 0.000000
1 0.000000
2 0.028573
3 -0.043172
4 0.000000
...
851 -0.012821
852 -0.026145
853 0.006601
854 0.008734
855 0.002172
Name: lnDeltaP, Length: 856, dtype: float64Det viser seg at i aksjemarkedet, så har aksjene en tendens til å bevege seg i samme retning. Går børsen først ned, så vil det gjelde de aller fleste aksjene på børsen. Gjennomsnittetlig avkastning for alle børsens aksjer måles av børsindeksen. I Titlon er børsindeksen lagt inn som en variabel for hvert selskap under navnet lnDeltaOSEBX. La oss derfor undersøke om det stemmer at det er en nær sammenheng mellom Equinors kurs og børsindeksen, ved hjelp av matplotlib:
df.plot.scatter('lnDeltaP','lnDeltaOSEBX')<AxesSubplot: xlabel='lnDeltaP', ylabel='lnDeltaOSEBX'>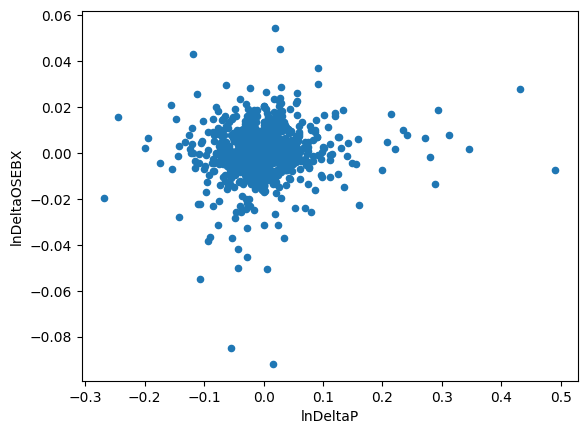
Du kan finne informasjon om andre aksjer enn Equinor om du vil. Koden under kjører en SQL-spørring som henter navnene på alle selskap i databasen etter 2018. Om du vil hente ut et annet selskap, kan du velge blant disse
sql="SELECT distinct `Name`,`ISIN`,`SecurityId`,CompanyId FROM equity WHERE Year(`Date`)>2018 ORDER BY `Name`"
companies = pd.read_sql_query(sql, con)
list(companies.values)C:\Users\esi000\AppData\Local\Temp\ipykernel_25488\3379528039.py:2: UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.
companies = pd.read_sql_query(sql, con)[array(['2020 Bulkers', 'BMG9156K1018', 1304857, 12720], dtype=object),
array(['5th Planet Games', 'DK0060945467', 1301972, 12440], dtype=object),
array(['ABG Sundal Collier Holding', 'NO0003021909', 6085, 2017],
dtype=object),
array(['Adevinta', 'NO0010844038', 1304655, 12701], dtype=object),
array(['Adevinta ser. A', 'NO0010843998', 1304652, 12701], dtype=object),
array(['Aega', 'NO0010626559', 1251504, 11273], dtype=object),
array(['AF Gruppen', 'NO0003078107', 27028, 6051], dtype=object),
array(['African Petroleum Corporation', 'AU000000AOQ0', 1301079, 12300],
dtype=object),
array(['Agasti Holding', 'NO0003108102', 49006, 6806], dtype=object),
array(['Akastor', 'NO0010215684', 56655, 7765], dtype=object),
array(['Aker', 'NO0010234552', 57522, 6047], dtype=object),
array(['Aker BP', 'NO0010345853', 66985, 8376], dtype=object),
array(['Aker Philadelphia Shipyard', 'NO0010395577', 68945, 8462],
dtype=object),
array(['Aker Solutions', 'NO0010716582', 1301283, 12353], dtype=object),
array(['AKVA Group', 'NO0003097503', 63319, 8194], dtype=object),
array(['American Shipping Company', 'NO0010272065', 59576, 7954],
dtype=object),
array(['Apptix', 'NO0010123060', 51128, 7072], dtype=object),
array(['Aqua Bio Technology', 'NO0010307135', 68900, 8465], dtype=object),
array(['Aqualis', 'NO0010715394', 1301198, 12348], dtype=object),
array(['Archer', 'BMG0451H1170', 1249973, 11216], dtype=object),
array(['Arcus', 'NO0010776875', 1302776, 12523], dtype=object),
array(['Arendals Fossekompani', 'NO0003572802', 6006, 1007], dtype=object),
array(['Asetek', 'DK0060477263', 1300289, 11324], dtype=object),
array(['Atea', 'NO0004822503', 6157, 2305], dtype=object),
array(['Atlantic Petroleum', 'FO000A0DN9X4', 1300746, 11657], dtype=object),
array(['Atlantic Sapphire', 'NO0010768500', 1304025, 12625], dtype=object),
array(['Aurskog Sparebank', 'NO0006001601', 34079, 6131], dtype=object),
array(['Austevoll Seafood', 'NO0010073489', 63004, 8163], dtype=object),
array(['Avance Gas Holding', 'BMG067231032', 1300995, 12290], dtype=object),
array(['Avocet Mining', 'GB00BZBVR613', 1249085, 11178], dtype=object),
array(['Awilco Drilling', 'GB00B5LJSC86', 1250770, 11244], dtype=object),
array(['Awilco LNG', 'NO0010607971', 1251293, 11268], dtype=object),
array(['Axactor', 'NO0010840515', 28597, 6084], dtype=object),
array(['Axxis Geo Solutions', 'NO0010778095', 1302814, 12534],
dtype=object),
array(['B2Holding', 'NO0010633951', 1302448, 12485], dtype=object),
array(['Badger Explorer', 'NO0010283211', 65258, 8360], dtype=object),
array(['Bakkafrost', 'FO0000000179', 81451, 8620], dtype=object),
array(['Belships', 'NO0003094104', 6026, 2221], dtype=object),
array(['Bergen Group', 'NO0010379779', 70904, 8495], dtype=object),
array(['BerGenBio', 'NO0010650013', 1303054, 12550], dtype=object),
array(['Bionor Pharma', 'NO0003106700', 45901, 6339], dtype=object),
array(['Biotec Pharmacon', 'NO0010014632', 60209, 7963], dtype=object),
array(['Birdstep Technology', 'NO0003095309', 51606, 7150], dtype=object),
array(['Blom', 'NO0003679102', 6034, 2230], dtype=object),
array(['Bonheur', 'NO0003110603', 6037, 2208], dtype=object),
array(['Borgestad', 'NO0003111700', 6038, 2209], dtype=object),
array(['Borr Drilling', 'BMG1466R2078', 1303306, 12565], dtype=object),
array(['Borregaard', 'NO0010657505', 1270371, 11306], dtype=object),
array(['Bouvet', 'NO0010360266', 65052, 8307], dtype=object),
array(['BW Energy Limited', 'BMG0702P1086', 1305295, 12748], dtype=object),
array(['BW LPG', 'BMG173841013', 1300695, 12241], dtype=object),
array(['BW Offshore Limited', 'BMG1738J1247', 61979, 8108], dtype=object),
array(['Byggma', 'NO0003087603', 26940, 6049], dtype=object),
array(['ContextVision', 'SE0000371239', 23281, 6006], dtype=object),
array(['ContextVision', 'SE0014731154', 23281, 6006], dtype=object),
array(['Crayon Group Holding', 'NO0010808892', 1303474, 12400],
dtype=object),
array(['Cxense', 'NO0010671068', 1301162, 12305], dtype=object),
array(['Data Respons', 'NO0003064107', 28775, 6085], dtype=object),
array(['DNB', 'NO0010031479', 6059, 1772], dtype=object),
array(['DNB OBX', 'NO0010257801', 58573, 7834], dtype=object),
array(['DNO', 'NO0003921009', 6065, 1015], dtype=object),
array(['DOF', 'NO0010070063', 46930, 6489], dtype=object),
array(['EAM Solar', 'NO0010607781', 1300298, 11296], dtype=object),
array(['Eidesvik Offshore', 'NO0010263023', 59496, 7942], dtype=object),
array(['Electromagnetic Geoservices', 'NO0010358484', 64806, 8264],
dtype=object),
array(['Element', 'NO0003055808', 63613, 8201], dtype=object),
array(['Elkem', 'NO0010816093', 1303941, 12616], dtype=object),
array(['Entra', 'NO0010716418', 1301320, 12366], dtype=object),
array(['Equinor', 'NO0010096985', 15578, 1309], dtype=object),
array(['Europris', 'NO0010735343', 1301946, 12441], dtype=object),
array(['EVRY', 'NO0010019649', 44547, 6176], dtype=object),
array(['EVRY', 'NO0010019649', 1303207, 12559], dtype=object),
array(['Fjord1', 'NO0010792625', 1303125, 12556], dtype=object),
array(['Fjordkraft Holding', 'NO0010815673', 1303929, 12598], dtype=object),
array(['FLEX LNG', 'BMG359472021', 79729, 8594], dtype=object),
array(['Fred. Olsen Energy', 'NO0003089005', 27721, 6063], dtype=object),
array(['Frontline', 'BMG3682E1921', 38027, 6117], dtype=object),
array(['Funcom', 'NL0012756266', 60667, 7997], dtype=object),
array(['Funcom', 'NO0010887029', 60667, 7997], dtype=object),
array(['Gaming Innovation Group', 'US36467X2062', 58337, 7829],
dtype=object),
array(['GC Rieber Shipping', 'NO0010262686', 58609, 7837], dtype=object),
array(['Gjensidige Forsikring', 'NO0010582521', 1249975, 11217],
dtype=object),
array(['Golden Ocean Group', 'BMG396372051', 1301610, 12424], dtype=object),
array(['Goodtech', 'NO0004913609', 6105, 2312], dtype=object),
array(['Grieg Seafood', 'NO0010365521', 65259, 8362], dtype=object),
array(['Gyldendal', 'NO0004288200', 6108, 2269], dtype=object),
array(['Hafnia Limited', 'BMG4233B1090', 1305074, 12741], dtype=object),
array(['Havila Shipping', 'NO0010257728', 59268, 7928], dtype=object),
array(['Havyard Group', 'NO0010708605', 1301163, 12289], dtype=object),
array(['Helgeland Sparebank', 'NO0010029804', 45402, 6053], dtype=object),
array(['Hexagon Composites', 'NO0003067902', 17151, 5203], dtype=object),
array(['Höegh LNG Holdings', 'BMG454221059', 1251127, 11251], dtype=object),
array(['Hofseth BioCare', 'NO0010598683', 1258882, 11280], dtype=object),
array(['Høland og Setskog Sparebank', 'NO0010012636', 44223, 6171],
dtype=object),
array(['Ice Group', 'NO0010734742', 1304735, 12680], dtype=object),
array(['IDEX', 'NO0003070609', 81220, 8606], dtype=object),
array(['Indre Sogn Sparebank', 'NO0006000603', 17135, 5202], dtype=object),
array(['Infront', 'NO0010789506', 1303390, 12561], dtype=object),
array(['Insr Insurance Group', 'NO0010593544', 1300977, 12272],
dtype=object),
array(['InterOil Exploration and Production', 'NO0010284318', 62361, 8135],
dtype=object),
array(['Itera', 'NO0010001118', 39773, 6153], dtype=object),
array(['Jæren Sparebank', 'NO0010359433', 65050, 6483], dtype=object),
array(['Jinhui Shipping and Transportation', 'BMG5137R1088', 15440, 2446],
dtype=object),
array(['Kid', 'NO0010743545', 1302115, 12451], dtype=object),
array(['Kitron', 'NO0003079709', 29719, 6098], dtype=object),
array(['Klaveness Combination Carriers', 'NO0010833262', 1304742, 12197],
dtype=object),
array(['Komplett Bank', 'NO0010694029', 1303481, 12484], dtype=object),
array(['Kongsberg Automotive', 'NO0003033102', 15825, 2518], dtype=object),
array(['Kongsberg Automotive', 'NO0003033102', 59485, 7941], dtype=object),
array(['Kongsberg Gruppen', 'NO0003043309', 6177, 2331], dtype=object),
array(['Kværner', 'NO0010605371', 1251131, 11252], dtype=object),
array(['Lerøy Seafood Group', 'NO0003096208', 51529, 7148], dtype=object),
array(['Link Mobility Group Holding', 'NO0010894231', 1305713, 12811],
dtype=object),
array(['Magnora', 'NO0010187032', 58030, 7820], dtype=object),
array(['Magseis', 'NO0010663669', 1301093, 12301], dtype=object),
array(['Marine Harvest', 'NO0003054108', 16258, 5063], dtype=object),
array(['Medistim', 'NO0010159684', 57018, 7774], dtype=object),
array(['Melhus Sparebank', 'NO0006001908', 38026, 6147], dtype=object),
array(['Mindex', 'NO0003055808', 16501, 5112], dtype=object),
array(['MPC Container Ships', 'NO0010791353', 1303147, 12557],
dtype=object),
array(['Multiconsult', 'NO0010734338', 1301887, 12437], dtype=object),
array(['Napatech', 'DK0060520450', 1300730, 12233], dtype=object),
array(['NattoPharma', 'NO0010289200', 68905, 8447], dtype=object),
array(['Navamedic', 'NO0010205966', 61513, 8063], dtype=object),
array(['Nekkar', 'NO0003049405', 15900, 2525], dtype=object),
array(['NEL', 'NO0010081235', 57456, 7795], dtype=object),
array(['NEXT Biometrics Group', 'NO0010629108', 1301145, 12309],
dtype=object),
array(['NextGenTel Holding', 'NO0010199052', 61983, 8112], dtype=object),
array(['NORBIT', 'NO0010856511', 1304825, 12714], dtype=object),
array(['Nordic Mining', 'NO0010317340', 67633, 8123], dtype=object),
array(['Nordic Nanovector', 'NO0010597883', 1301592, 12412], dtype=object),
array(['Nordic Semiconductor', 'NO0003055501', 16511, 5117], dtype=object),
array(['Norsk Hydro', 'NO0005052605', 6180, 1114], dtype=object),
array(['Norske Skog', 'NO0010861115', 1305028, 12734], dtype=object),
array(['North Energy', 'NO0010550056', 81219, 8605], dtype=object),
array(['Northern Drilling', 'BMG6624L1090', 1303448, 12568], dtype=object),
array(['Northern Ocean Ltd.', 'BMG6682J1036', 1305313, 12750],
dtype=object),
array(['Norway Royal Salmon', 'NO0010331838', 1250275, 11235],
dtype=object),
array(['Norwegian Air Shuttle', 'NO0010196140', 55463, 7628], dtype=object),
array(['Norwegian Energy Company', 'NO0010379266', 68236, 8416],
dtype=object),
array(['Norwegian Finans Holding', 'NO0010387004', 1302477, 12494],
dtype=object),
array(['Norwegian Property', 'NO0010317811', 63318, 8191], dtype=object),
array(['NTS', 'NO0004895103', 6169, 2311], dtype=object),
array(['Observe Medical', 'NO0010865009', 1305053, 12733], dtype=object),
array(['Ocean Yield', 'NO0010657448', 1300504, 11316], dtype=object),
array(['Oceanteam', 'NO0010317316', 63829, 8229], dtype=object),
array(['Odfjell Drilling', 'BMG671801022', 1300591, 12219], dtype=object),
array(['Odfjell ser. A', 'NO0003399909', 6269, 2366], dtype=object),
array(['Odfjell ser. B', 'NO0003399917', 6270, 2366], dtype=object),
array(['OKEA', 'NO0010816895', 1304819, 12627], dtype=object),
array(['Okeanis Eco Tankers', 'MHY641771016', 1304141, 12643],
dtype=object),
array(['Olav Thon Eiendomsselskap', 'NO0005638858', 6212, 1308],
dtype=object),
array(['Opera Software', 'NO0010040611', 56454, 7759], dtype=object),
array(['Orkla', 'NO0003733800', 6214, 1107], dtype=object),
array(['Panoro Energy', 'NO0010564701', 81450, 8624], dtype=object),
array(['Pareto Bank', 'NO0010397581', 1302433, 8596], dtype=object),
array(['PCI Biotech Holding', 'NO0010405640', 71329, 8502], dtype=object),
array(['Petroleum Geo-Services', 'NO0010199151', 6220, 2342], dtype=object),
array(['Petrolia', 'CY0102630916', 24518, 6018], dtype=object),
array(['PetroNor E&P Limited', 'AU0000057408', 1301079, 12300],
dtype=object),
array(['Pexip Holding', 'NO0010840507', 1305435, 12767], dtype=object),
array(['Photocure', 'NO0010000045', 46096, 6357], dtype=object),
array(['Pioneer Property Group', 'NO0010735681', 1301947, 12438],
dtype=object),
array(['Polarcus', 'KYG7153K1085', 79256, 8582], dtype=object),
array(['Polaris Media', 'NO0010466022', 73803, 8537], dtype=object),
array(['poLight', 'NO0010341712', 1304302, 12664], dtype=object),
array(['Prosafe', 'NO0010861990', 24019, 6010], dtype=object),
array(['Protector Forsikring', 'NO0010209331', 65045, 8322], dtype=object),
array(['PSI Group', 'NO0010098247', 48772, 6793], dtype=object),
array(['Q-Free', 'NO0003103103', 51098, 7065], dtype=object),
array(['Questerre Energy Corporation', 'CA74836K1003', 59363, 7938],
dtype=object),
array(['RAK Petroleum', 'GB00BRGBL804', 1301358, 12373], dtype=object),
array(['Reach Subsea', 'NO0003117202', 6195, 2319], dtype=object),
array(['REC Silicon', 'NO0010112675', 61696, 8080], dtype=object),
array(['RomReal', 'BMG763301022', 65262, 8353], dtype=object),
array(['S.D. Standard Drilling', 'CY0101550917', 1250271, 11233],
dtype=object),
array(['Saga Pure', 'NO0010572589', 1249132, 11191], dtype=object),
array(['SalMar', 'NO0010310956', 65055, 8288], dtype=object),
array(['Salmones Camanchaca', 'CL0002409135', 1303837, 12593],
dtype=object),
array(['Sandnes Sparebank', 'NO0006001007', 16189, 5024], dtype=object),
array(['SAS AB', 'SE0003366871', 48943, 1387], dtype=object),
array(['SATS', 'NO0010863285', 1305040, 12737], dtype=object),
array(['Sbanken', 'NO0010739402', 1302111, 12452], dtype=object),
array(['Scana', 'NO0003053308', 16226, 5059], dtype=object),
array(['Scanship Holding', 'NO0010708068', 1300985, 12294], dtype=object),
array(['Scatec', 'NO0010715139', 1301292, 12354], dtype=object),
array(['Schibsted', 'NO0003028904', 6240, 2354], dtype=object),
array(['Schibsted ser. B', 'NO0010736879', 1301905, 2354], dtype=object),
array(['SeaBird Exploration', 'CY0101162119', 61088, 8025], dtype=object),
array(['Seadrill', 'BMG7998G1069', 1304153, 7968], dtype=object),
array(['Self Storage Group', 'NO0010781206', 1303451, 12578], dtype=object),
array(['Selvaag Bolig', 'NO0010612450', 1267552, 11291], dtype=object),
array(['Shelf Drilling', 'KYG236271055', 1304120, 12640], dtype=object),
array(['Siem Offshore', 'KYG813131011', 60065, 7956], dtype=object),
array(['Skue Sparebank', 'NO0006001809', 37518, 6143], dtype=object),
array(['Solstad Farstad', 'NO0003080608', 27953, 6066], dtype=object),
array(['SpareBank 1 BV', 'NO0006000207', 15145, 2352], dtype=object),
array(['SpareBank 1 Nord-Norge', 'NO0006000801', 15121, 1972],
dtype=object),
array(['SpareBank 1 Nordvest', 'NO0010691660', 1303395, 1823],
dtype=object),
array(['SpareBank 1 Østfold Akershus', 'NO0010285562', 60387, 5195],
dtype=object),
array(['SpareBank 1 Østlandet', 'NO0010751910', 1303168, 5204],
dtype=object),
array(['SpareBank 1 Ringerike Hadeland', 'NO0006390400', 16545, 5125],
dtype=object),
array(['SpareBank 1 SMN', 'NO0006390301', 15120, 1695], dtype=object),
array(['SpareBank 1 SR-Bank', 'NO0010631567', 1264688, 1797], dtype=object),
array(['Sparebanken Møre', 'NO0006390004', 6163, 1652], dtype=object),
array(['Sparebanken Øst', 'NO0006222009', 6073, 1636], dtype=object),
array(['Sparebanken Sør', 'NO0006001502', 34078, 1814], dtype=object),
array(['Sparebanken Telemark', 'NO0010664782', 1304311, 8332],
dtype=object),
array(['Sparebanken Vest', 'NO0006000900', 15669, 1642], dtype=object),
array(['Spectrum', 'NO0010429145', 71330, 8507], dtype=object),
array(['Star Bulk Carriers', 'MHY8162K2046', 1304148, 12642], dtype=object),
array(['Stolt-Nielsen', 'BMG850801025', 16466, 5097], dtype=object),
array(['Storebrand', 'NO0003053605', 6288, 1955], dtype=object),
array(['Storm Real Estate', 'NO0010360175', 1249133, 11189], dtype=object),
array(['Subsea 7', 'LU0075646355', 25289, 6030], dtype=object),
array(['Targovax', 'NO0010689326', 1302524, 12499], dtype=object),
array(['Team Tankers International', 'BMG870871057', 1301566, 12413],
dtype=object),
array(['Telenor', 'NO0010063308', 47454, 6233], dtype=object),
array(['TGS-NOPEC Geophysical Company', 'NO0003078800', 28494, 6070],
dtype=object),
array(['The Scottish Salmon Company', 'JE00B61ZHN74', 81453, 8623],
dtype=object),
array(['Thin Film Electronics', 'NO0010299068', 68907, 8458], dtype=object),
array(['TietoEVRY', 'FI0009000277', 1305127, 12743], dtype=object),
array(['Tomra Systems', 'NO0005668905', 6282, 2392], dtype=object),
array(['Totens Sparebank', 'NO0006001205', 16224, 1662], dtype=object),
array(['Treasure', 'NO0010763550', 1302445, 12495], dtype=object),
array(['Ultimovacs', 'NO0010851603', 1304776, 12711], dtype=object),
array(['Veidekke', 'NO0005806802', 6296, 2400], dtype=object),
array(['Vistin Pharma', 'NO0010734122', 1301918, 12436], dtype=object),
array(['Voss Veksel- og Landmandsbank', 'NO0003025009', 6306, 2403],
dtype=object),
array(['Wallenius Wilhelmsen', 'NO0010571680', 1249129, 11186],
dtype=object),
array(['Webstep', 'NO0010609662', 1303418, 12575], dtype=object),
array(['Wentworth Resources', 'JE00BGT34J81', 59574, 7953], dtype=object),
array(['Wilh. Wilhelmsen Holding ser. A', 'NO0010571698', 6310, 2405],
dtype=object),
array(['Wilh. Wilhelmsen Holding ser. B', 'NO0010576010', 6311, 2405],
dtype=object),
array(['Wilson', 'NO0010252356', 58630, 7915], dtype=object),
array(['XACT OBX', 'SE0009723026', 58840, 7918], dtype=object),
array(['XACT OBX Bear', 'SE0009723000', 69842, 7918], dtype=object),
array(['XACT OBX Bull', 'SE0009723034', 69843, 7918], dtype=object),
array(['XXL', 'NO0010716863', 1301298, 12357], dtype=object),
array(['Yara International', 'NO0010208051', 56559, 7760], dtype=object),
array(['Zalaris', 'NO0010708910', 1301140, 12310], dtype=object)]La oss se nærmere på tre av selskapene, og plott dem sammen. Vi bruker en SQL WHERE-betingelse til å begrense utvalget til de tre selskapene som er nevnt og til datoer etter 2000. Så tar vi også med i SQL-setningen en sortering på dato:
sql=("SELECT distinct Name,date, AdjustedPrice FROM equity "
"WHERE (Name='Equinor' OR Name='Tomra Systems' OR Name='DNB') "
"AND `Date`>'2000-01-01'"
"ORDER BY `Date`")Vi kan nå kjøre denne spørringen mot Titlon:
df=pd.read_sql_query(sql, con)
dfC:\Users\esi000\AppData\Local\Temp\ipykernel_25488\1427550990.py:1: UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.
df=pd.read_sql_query(sql, con)| Name | date | AdjustedPrice | |
|---|---|---|---|
| 0 | DNB | 2000-01-03 | 13.5376 |
| 1 | Tomra Systems | 2000-01-03 | 48.2225 |
| 2 | DNB | 2000-01-04 | 13.0850 |
| 3 | Tomra Systems | 2000-01-04 | 47.5133 |
| 4 | DNB | 2000-01-05 | 12.6735 |
| ... | ... | ... | ... |
| 15376 | Equinor | 2020-11-26 | 143.7500 |
| 15377 | Tomra Systems | 2020-11-26 | 382.8000 |
| 15378 | DNB | 2020-11-27 | 163.5500 |
| 15379 | Equinor | 2020-11-27 | 146.8500 |
| 15380 | Tomra Systems | 2020-11-27 | 386.1000 |
15381 rows × 3 columns
Dataene ligger nå i “lengdeformat”. Det vil si at selskapene ligger etterhverandre i en lang tabell. Om vi ønsker å sammenligne utviklingen kan det være en fordel å få prisene i hvert selskap i en egen kolonne. Det gjør vi slik:
df=df.pivot(index='date', columns='Name', values='AdjustedPrice')
df| Name | DNB | Equinor | Tomra Systems |
|---|---|---|---|
| date | |||
| 2000-01-03 | 13.5376 | NaN | 48.2225 |
| 2000-01-04 | 13.0850 | NaN | 47.5133 |
| 2000-01-05 | 12.6735 | NaN | 46.0950 |
| 2000-01-06 | 12.5500 | NaN | 45.3859 |
| 2000-01-07 | 12.5500 | NaN | 46.6269 |
| ... | ... | ... | ... |
| 2020-11-23 | 159.0000 | 141.25 | 370.2000 |
| 2020-11-24 | 163.8000 | 148.65 | 371.6000 |
| 2020-11-25 | 164.1000 | 145.75 | 376.8000 |
| 2020-11-26 | 162.5000 | 143.75 | 382.8000 |
| 2020-11-27 | 163.5500 | 146.85 | 386.1000 |
5248 rows × 3 columns
Equinor ble imidlertid ikke børsnotert før i 2001. I alle observasjoner før børsnoteringen står det derfor NaN, hvilket betyr “ingen observasjon”. For å kunne sammenligne må alle tre aksjene være observert på hver dato. Vi kan oppnå dette med funksjonen dropna():
df=df.dropna()
df| Name | DNB | Equinor | Tomra Systems |
|---|---|---|---|
| date | |||
| 2001-06-18 | 17.8950 | 28.1166 | 117.493 |
| 2001-06-19 | 17.9867 | 28.5241 | 108.236 |
| 2001-06-20 | 18.3997 | 28.9315 | 108.948 |
| 2001-06-21 | 18.2620 | 28.5241 | 103.608 |
| 2001-06-22 | 18.3079 | 28.3203 | 100.759 |
| ... | ... | ... | ... |
| 2020-11-23 | 159.0000 | 141.2500 | 370.200 |
| 2020-11-24 | 163.8000 | 148.6500 | 371.600 |
| 2020-11-25 | 164.1000 | 145.7500 | 376.800 |
| 2020-11-26 | 162.5000 | 143.7500 | 382.800 |
| 2020-11-27 | 163.5500 | 146.8500 | 386.100 |
4885 rows × 3 columns
Vi ser nå at de tomme cellene er borte. Equinor ble altså børsnotert 18. juni 2001.
For å kunne sammenligne selskapenes utvikling bedre, bør de starte på samme tidspunkt. For å gjøre det deler vi alle observasjonene på den første. For å dele observasjoner på noe, bruker vi div()-funksjonen til datarammen. Vi skal dele på første rad, som er df.iloc[0]. Så multipliserer vi det hele med 100:
df=100*df.div(df.iloc[0])
df| Name | DNB | Equinor | Tomra Systems |
|---|---|---|---|
| date | |||
| 2001-06-18 | 100.000000 | 100.000000 | 100.000000 |
| 2001-06-19 | 100.512434 | 101.449322 | 92.121233 |
| 2001-06-20 | 102.820341 | 102.898288 | 92.727226 |
| 2001-06-21 | 102.050852 | 101.449322 | 88.182275 |
| 2001-06-22 | 102.307348 | 100.724483 | 85.757449 |
| ... | ... | ... | ... |
| 2020-11-23 | 888.516345 | 502.372264 | 315.082601 |
| 2020-11-24 | 915.339480 | 528.691236 | 316.274161 |
| 2020-11-25 | 917.015926 | 518.377044 | 320.699957 |
| 2020-11-26 | 908.074881 | 511.263809 | 325.806644 |
| 2020-11-27 | 913.942442 | 522.289324 | 328.615322 |
4885 rows × 3 columns
Vi ser nå at alle aksjene starter på 100 den datoen Equinor ble børsnotert. Hvilet selskap har vært det beste å investere i? Hvilket har vært verst?
Vi kan nå plotte utviklingen. Når vi jobber med pandas, er det best å bruke den innebygde plot()-funksjonen i pakken. Da får vi automatisk riktige etiketter:
ax=df.plot()
ax.legend(loc='upper left',frameon=False)<matplotlib.legend.Legend at 0x1842f9fa350>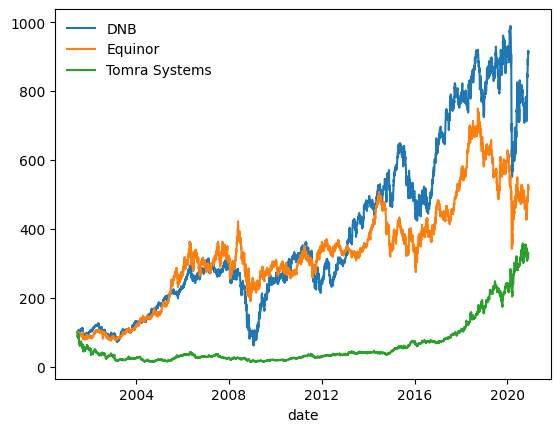
Eurostat er en veldig nyttig kilde til data. De har et stort utvalg av data på europeiske land. De har laget en egen pakke til python som ikke overraskende heter eurostat. Denne pakken er heller ikke installert i utgangspunktet på jupyter.uit.no. Dere må derfor åpne “Terminal” og kjøre pip install eurostat for å kjøre den.
For å se hvilke tabeller som er der, henter vi innholdsfortegnelsen (table of contents) med funksjonen get_toc_df. Det gir oss en pandas dataramme:
import eurostat
toc = eurostat.get_toc_df()
toc| title | code | type | last update of data | last table structure change | data start | data end | |
|---|---|---|---|---|---|---|---|
| 0 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_NL | dataset | 2010-02-26T23:00:00+0100 | 2023-07-28T23:00:00+0200 | 1997-Q1 | 2022-Q4 |
| 1 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_NO | dataset | 2010-02-26T23:00:00+0100 | 2023-07-28T23:00:00+0200 | 2002-Q1 | 2021-Q4 |
| 2 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_PL | dataset | 2023-09-12T11:00:00+0200 | 2023-09-12T11:00:00+0200 | 2004-Q1 | 2023-Q1 |
| 3 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_PT | dataset | 2023-09-19T11:00:00+0200 | 2023-09-19T11:00:00+0200 | 2000-Q1 | 2023-Q1 |
| 4 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_SE | dataset | 2010-02-26T23:00:00+0100 | 2023-07-28T23:00:00+0200 | 1997-Q1 | 2022-Q4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 7545 | Percentage of letters delivered on-time (USP u... | POST_CUBE1_X$POST_QOS_1 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
| 7546 | Postal services | POST_CUBE1_X | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | 2012 | 2021 |
| 7547 | Number of enterprises providing postal services | POST_CUBE1_X$NUM701 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
| 7548 | Access points (USP under direct or indirect d... | POST_CUBE1_X$POST_ACC_1 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
| 7549 | Domestic postal traffic, letter mail and parce... | POST_CUBE1_X$POST_DTR_1 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
7550 rows × 7 columns
Du kan finne hvor mange tabeller det er med len(toc), og det er i skrivende stund over ti tusen tabeller. Det blir litt krevende å lete gjennom alle, så vi ønsker derfor å begrense antall tabeller til de som er relevante. Anta at vi ønsker å se på utviklingen i BNP per innbygger for landene som er med i statistikken. Nærmere bestemt, vi ønsker å finne alle tabeller der 'GDP per capita' er i tittelen.
BNP per innbygger er hvor mye hver person i landet i gjennomsnitt produserer i løpet av ett år.
Vi gjør dette ved å lage følgende “list comprehension”: ['GDP per capita' in i for i in toc['title']]. Elementene i denne listen er sant (True) dersom ‘GDP per capita’ er i tittelen, og usant (false) om det ikke er i tittelen.
gdp_in_toc_list=['GDP per capita' in i for i in toc['title']]Vi kan så velge de elementene hvor betingelsen er sann ved å sette listen inn i en klammeparentes etter innholdsfortegnelsen, toc[gdp_in_toc_list]. Kun de elementene i innholdsfortegnelsen der det står sant (True) i listen, tas da med.
#collecting only the tables where 'GDP per capita' is in the name
toc_gdp=toc[gdp_in_toc_list]
toc_gdp| title | code | type | last update of data | last table structure change | data start | data end | |
|---|---|---|---|---|---|---|---|
| 5486 | GDP per capita in PPS | TEC00114 | dataset | 2023-06-21T23:00:00+0200 | 2023-06-21T23:00:00+0200 | 2011 | 2022 |
| 6444 | Real GDP per capita | SDG_08_10 | dataset | 2023-10-12T11:00:00+0200 | 2023-10-12T11:00:00+0200 | 2000 | 2022 |
| 6478 | Purchasing power adjusted GDP per capita | SDG_10_10 | dataset | 2023-06-21T23:00:00+0200 | 2023-06-21T23:00:00+0200 | 2000 | 2022 |
La oss nå se på tabellen “Purchasing power adjusted GDP per capita”, som har kode ‘sdg_10_10’. Da bruker vi funksjonen get_data_df med tabellkoden som argument:
gdp_data = eurostat.get_data_df('sdg_10_10')
gdp_data| freq | na_item | ppp_cat | unit | geo\TIME_PERIOD | 2000 | 2001 | 2002 | 2003 | 2004 | ... | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A | CV_VI_HAB | GDP | PC | EA19 | 45.9 | 44.2 | 43.2 | 41.6 | 41.8 | ... | 43.3 | 43.7 | 44.8 | 44.1 | 42.7 | 41.5 | 39.9 | 42.8 | 44.4 | 44.5 |
| 1 | A | CV_VI_HAB | GDP | PC | EA20 | 47.6 | 45.7 | 44.5 | 42.9 | 43.0 | ... | 44.1 | 44.7 | 45.8 | 44.9 | 43.5 | 42.3 | 40.6 | 43.6 | 44.9 | 44.8 |
| 2 | A | CV_VI_HAB | GDP | PC | EU27_2007 | 49.8 | 48.0 | 46.8 | 45.2 | 44.9 | ... | 43.0 | 43.1 | 44.1 | 43.2 | 41.8 | 40.5 | 38.7 | 40.9 | NaN | NaN |
| 3 | A | CV_VI_HAB | GDP | PC | EU27_2020 | 51.8 | 49.9 | 48.5 | 46.8 | 46.5 | ... | 44.4 | 44.6 | 45.5 | 44.6 | 43.1 | 41.7 | 39.8 | 42.1 | 43.2 | 42.8 |
| 4 | A | CV_VI_HAB | GDP | PC | EU28 | 50.6 | 48.8 | 47.5 | 45.8 | 45.5 | ... | 43.5 | 43.7 | 44.6 | 43.7 | 42.2 | 41.1 | 39.6 | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 88 | A | VI_PPS_EU27_2020_HAB | GDP | PC | SI | 81.0 | 82.0 | 83.0 | 85.0 | 88.0 | ... | 83.0 | 83.0 | 83.0 | 84.0 | 86.0 | 87.0 | 89.0 | 89.0 | 90.0 | 92.0 |
| 89 | A | VI_PPS_EU27_2020_HAB | GDP | PC | SK | 51.0 | 53.0 | 55.0 | 57.0 | 59.0 | ... | 78.0 | 78.0 | 79.0 | 73.0 | 71.0 | 70.0 | 71.0 | 72.0 | 71.0 | 68.0 |
| 90 | A | VI_PPS_EU27_2020_HAB | GDP | PC | TR | 43.0 | 39.0 | 38.0 | 39.0 | 42.0 | ... | 62.0 | 65.0 | 68.0 | 66.0 | 66.0 | 63.0 | 59.0 | 61.0 | 63.0 | 69.0 |
| 91 | A | VI_PPS_EU27_2020_HAB | GDP | PC | UK | 120.0 | 120.0 | 120.0 | 123.0 | 124.0 | ... | 111.0 | 111.0 | 111.0 | 109.0 | 108.0 | 106.0 | 104.0 | 100.0 | 101.0 | 100.0 |
| 92 | A | VI_PPS_EU27_2020_HAB | GDP | PC | US | 164.0 | 160.0 | 156.0 | 159.0 | 161.0 | ... | 147.0 | 148.0 | 148.0 | 142.0 | 140.0 | 140.0 | 136.0 | 138.0 | 143.0 | 141.0 |
93 rows × 28 columns
Tabellen inneholder imidlertid endel data vi ikke ønsker å ha med. For det første ønsker vi kun å ta med tilfellene der feltet “na_item” er lik ‘EXP_PPS_EU27_2020_HAB’, for det andre er her dataene til hvert enkelt land ligger. Dette gjør vi på samme måte som over med listen gdp_data['na_item']=='EXP_PPS_EU27_2020_HAB', som er sann når “na_item” er lik ‘EXP_PPS_EU27_2020_HAB’. Setter vi inn denne listen i klammeparentes etter gdp_data får vi en filtrert liste:
gdp_data = gdp_data[gdp_data['na_item']=='EXP_PPS_EU27_2020_HAB']
gdp_data| freq | na_item | ppp_cat | unit | geo\TIME_PERIOD | 2000 | 2001 | 2002 | 2003 | 2004 | ... | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | AL | 3200.0 | 3600.0 | 3800.0 | 4100.0 | 4400.0 | ... | 7600.0 | 8100.0 | 8400.0 | 8400.0 | 8800.0 | 9200.0 | 9500.0 | 9200.0 | 10300.0 | 12000.0 |
| 6 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | AT | 24400.0 | 24600.0 | 25600.0 | 26400.0 | 27600.0 | ... | 34600.0 | 35000.0 | 35900.0 | 36600.0 | 37200.0 | 38600.0 | 39400.0 | 37500.0 | 39800.0 | 44100.0 |
| 7 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | BA | NaN | NaN | NaN | NaN | NaN | ... | 8000.0 | 8100.0 | 8500.0 | 8900.0 | 9200.0 | 9800.0 | 10200.0 | 9900.0 | 11100.0 | 12500.0 |
| 8 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | BE | 23100.0 | 23800.0 | 24800.0 | 25400.0 | 26200.0 | ... | 31500.0 | 32200.0 | 33200.0 | 33800.0 | 34600.0 | 35600.0 | 36800.0 | 35700.0 | 39000.0 | 42200.0 |
| 9 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | BG | 5300.0 | 5800.0 | 6400.0 | 6900.0 | 7500.0 | ... | 12000.0 | 12600.0 | 13200.0 | 13900.0 | 14700.0 | 15600.0 | 16600.0 | 16600.0 | 18600.0 | 20700.0 |
| 10 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | CH | 30200.0 | 31000.0 | 31500.0 | 31600.0 | 32600.0 | ... | 44500.0 | 45400.0 | 46900.0 | 46800.0 | 46800.0 | 47900.0 | 47900.0 | 46400.0 | 50400.0 | 54300.0 |
| 11 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | CY | 17700.0 | 18900.0 | 19300.0 | 19900.0 | 21200.0 | ... | 22000.0 | 21600.0 | 22900.0 | 24900.0 | 26400.0 | 27600.0 | 29100.0 | 27100.0 | 29400.0 | 32300.0 |
| 12 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | CZ | 13500.0 | 14600.0 | 15000.0 | 16000.0 | 17100.0 | ... | 22200.0 | 23300.0 | 24400.0 | 25100.0 | 26700.0 | 27900.0 | 29200.0 | 28000.0 | 29700.0 | 32000.0 |
| 13 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | DE | 22800.0 | 23700.0 | 24200.0 | 24800.0 | 25900.0 | ... | 32500.0 | 33700.0 | 34200.0 | 35100.0 | 36500.0 | 37400.0 | 37900.0 | 37000.0 | 39000.0 | 41200.0 |
| 14 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | DK | 23800.0 | 24400.0 | 25100.0 | 25300.0 | 26900.0 | ... | 33700.0 | 34300.0 | 35300.0 | 36100.0 | 38000.0 | 39000.0 | 39500.0 | 39900.0 | 43000.0 | 48100.0 |
| 15 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EA19 | 21100.0 | 22000.0 | 22600.0 | 23100.0 | 23800.0 | ... | 28200.0 | 28700.0 | 29600.0 | 30300.0 | 31400.0 | 32300.0 | 33200.0 | 31600.0 | 34000.0 | 36700.0 |
| 16 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EA20 | 20900.0 | 21800.0 | 22500.0 | 22900.0 | 23700.0 | ... | 28000.0 | 28500.0 | 29400.0 | 30200.0 | 31200.0 | 32100.0 | 33100.0 | 31500.0 | 33900.0 | 36600.0 |
| 17 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EE | 7800.0 | 8500.0 | 9500.0 | 10700.0 | 11800.0 | ... | 19800.0 | 20700.0 | 21000.0 | 21700.0 | 23300.0 | 24700.0 | 25800.0 | 25800.0 | 28800.0 | 30700.0 |
| 18 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EL | 16200.0 | 17300.0 | 18500.0 | 19600.0 | 20800.0 | ... | 18800.0 | 19100.0 | 19200.0 | 19100.0 | 19600.0 | 20100.0 | 20600.0 | 18600.0 | 20700.0 | 23900.0 |
| 19 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | ES | 17900.0 | 19000.0 | 20000.0 | 20600.0 | 21400.0 | ... | 23400.0 | 24000.0 | 25100.0 | 25900.0 | 27200.0 | 27600.0 | 28500.0 | 24900.0 | 27000.0 | 29800.0 |
| 20 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EU27_2007 | 18900.0 | 19800.0 | 20400.0 | 21000.0 | 21900.0 | ... | 26500.0 | 27100.0 | 28000.0 | 28600.0 | 29700.0 | 30600.0 | 31600.0 | 30100.0 | NaN | NaN |
| 21 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EU27_2020 | 18400.0 | 19200.0 | 19900.0 | 20300.0 | 21200.0 | ... | 26000.0 | 26600.0 | 27500.0 | 28200.0 | 29300.0 | 30300.0 | 31300.0 | 30000.0 | 32500.0 | 35200.0 |
| 22 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EU28 | 18800.0 | 19700.0 | 20400.0 | 20900.0 | 21800.0 | ... | 26400.0 | 27000.0 | 27900.0 | 28500.0 | 29600.0 | 30500.0 | 31500.0 | 30000.0 | NaN | NaN |
| 23 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | FI | 22200.0 | 23000.0 | 23400.0 | 23800.0 | 25500.0 | ... | 29900.0 | 29900.0 | 30500.0 | 31200.0 | 32700.0 | 33600.0 | 34200.0 | 34300.0 | 36300.0 | 38400.0 |
| 24 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | FR | 21700.0 | 22800.0 | 23400.0 | 23100.0 | 23700.0 | ... | 28500.0 | 28800.0 | 29400.0 | 29800.0 | 30500.0 | 31400.0 | 33100.0 | 31400.0 | 33800.0 | 35800.0 |
| 25 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | HR | 8900.0 | 9600.0 | 10500.0 | 11200.0 | 12000.0 | ... | 16000.0 | 16000.0 | 16800.0 | 17600.0 | 18700.0 | 19600.0 | 20800.0 | 19500.0 | 22600.0 | 25700.0 |
| 26 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | HU | 9800.0 | 10900.0 | 11900.0 | 12700.0 | 13300.0 | ... | 17700.0 | 18400.0 | 19300.0 | 19400.0 | 20300.0 | 21600.0 | 22900.0 | 22400.0 | 24400.0 | 27300.0 |
| 27 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | IE | 25100.0 | 27000.0 | 28900.0 | 29800.0 | 31700.0 | ... | 34600.0 | 36700.0 | 49700.0 | 49800.0 | 53600.0 | 57500.0 | 59300.0 | 61600.0 | 70800.0 | 82100.0 |
| 28 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | IS | 24700.0 | 26400.0 | 26700.0 | 26900.0 | 29000.0 | ... | 32000.0 | 33000.0 | 35400.0 | 37200.0 | 38200.0 | 38800.0 | 39300.0 | 35600.0 | 38600.0 | 44900.0 |
| 29 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | IT | 22500.0 | 23200.0 | 23500.0 | 23900.0 | 24100.0 | ... | 26200.0 | 26100.0 | 26700.0 | 28000.0 | 28800.0 | 29400.0 | 30200.0 | 28300.0 | 30900.0 | 33700.0 |
| 30 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | JP | 22700.0 | 23100.0 | 23500.0 | 24100.0 | 25200.0 | ... | 28500.0 | 28300.0 | 29400.0 | 28200.0 | 28500.0 | 28700.0 | 28000.0 | 27400.0 | 28400.0 | 29700.0 |
| 31 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | LT | 7000.0 | 7800.0 | 8600.0 | 9900.0 | 10600.0 | ... | 19300.0 | 20200.0 | 20700.0 | 21500.0 | 23200.0 | 24700.0 | 26400.0 | 26300.0 | 29000.0 | 31500.0 |
| 32 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | LU | 45700.0 | 46400.0 | 48000.0 | 49300.0 | 52800.0 | ... | 72600.0 | 75200.0 | 77600.0 | 78500.0 | 78900.0 | 78900.0 | 78700.0 | 78500.0 | 87000.0 | 91900.0 |
| 33 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | LV | 6700.0 | 7500.0 | 8300.0 | 9100.0 | 10000.0 | ... | 16300.0 | 17100.0 | 18000.0 | 18600.0 | 19700.0 | 20900.0 | 21700.0 | 21600.0 | 23300.0 | 25900.0 |
| 34 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | ME | NaN | NaN | NaN | NaN | NaN | ... | 10700.0 | 11000.0 | 11700.0 | 12600.0 | 13500.0 | 14600.0 | 15700.0 | 13400.0 | 15500.0 | 17500.0 |
| 35 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | MK | 5100.0 | 5000.0 | 5200.0 | 5400.0 | 5900.0 | ... | 9200.0 | 9600.0 | 10000.0 | 10500.0 | 10800.0 | 11400.0 | 11900.0 | 11300.0 | 13700.0 | 14700.0 |
| 36 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | MT | 15300.0 | 15300.0 | 16100.0 | 17200.0 | 17600.0 | ... | 23300.0 | 24600.0 | 26900.0 | 27600.0 | 29800.0 | 30900.0 | 32400.0 | 29400.0 | 33100.0 | 36000.0 |
| 37 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | NL | 26500.0 | 27500.0 | 28200.0 | 28000.0 | 29300.0 | ... | 35500.0 | 35300.0 | 36200.0 | 36300.0 | 37800.0 | 39200.0 | 39700.0 | 39200.0 | 42000.0 | 45300.0 |
| 38 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | NO | 30700.0 | 31300.0 | 31200.0 | 31800.0 | 34900.0 | ... | 48600.0 | 47500.0 | 43700.0 | 41200.0 | 44400.0 | 47600.0 | 46100.0 | 42700.0 | 54300.0 | 74800.0 |
| 39 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | PL | 8900.0 | 9200.0 | 9700.0 | 10100.0 | 10900.0 | ... | 17300.0 | 17900.0 | 19000.0 | 19300.0 | 20300.0 | 21500.0 | 22800.0 | 22900.0 | 25100.0 | 28000.0 |
| 40 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | PT | 15700.0 | 16200.0 | 16700.0 | 17100.0 | 17500.0 | ... | 20200.0 | 20600.0 | 21300.0 | 22000.0 | 22700.0 | 23700.0 | 24600.0 | 22900.0 | 24400.0 | 27200.0 |
| 41 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | RO | 4900.0 | 5300.0 | 5900.0 | 6200.0 | 7300.0 | ... | 14200.0 | 14800.0 | 15500.0 | 16600.0 | 18500.0 | 20000.0 | 21800.0 | 21800.0 | 24000.0 | 27100.0 |
| 42 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | RS | 5000.0 | 5400.0 | 5900.0 | 6300.0 | 6900.0 | ... | 10600.0 | 10500.0 | 10700.0 | 11000.0 | 11400.0 | 12000.0 | 12800.0 | 12800.0 | 14300.0 | 15500.0 |
| 43 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | SE | 24600.0 | 24800.0 | 25300.0 | 26100.0 | 27700.0 | ... | 33400.0 | 33800.0 | 35300.0 | 35000.0 | 35700.0 | 36300.0 | 37200.0 | 36800.0 | 40000.0 | 42300.0 |
| 44 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | SI | 14900.0 | 15700.0 | 16600.0 | 17300.0 | 18600.0 | ... | 21600.0 | 22100.0 | 22700.0 | 23600.0 | 25100.0 | 26500.0 | 27800.0 | 26800.0 | 29200.0 | 32500.0 |
| 45 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | SK | 9400.0 | 10300.0 | 10900.0 | 11600.0 | 12400.0 | ... | 20200.0 | 20800.0 | 21600.0 | 20700.0 | 20700.0 | 21300.0 | 22100.0 | 21600.0 | 22900.0 | 24100.0 |
| 46 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | TR | 7900.0 | 7600.0 | 7600.0 | 7900.0 | 8900.0 | ... | 16100.0 | 17300.0 | 18600.0 | 18500.0 | 19400.0 | 19200.0 | 18500.0 | 18300.0 | 20300.0 | 24300.0 |
| 47 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | UK | 22000.0 | 23100.0 | 23800.0 | 24900.0 | 26200.0 | ... | 28900.0 | 29600.0 | 30600.0 | 30700.0 | 31700.0 | 32000.0 | 32500.0 | 30000.0 | 32900.0 | 35100.0 |
| 48 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | US | 30100.0 | 30700.0 | 31100.0 | 32400.0 | 34000.0 | ... | 38300.0 | 39400.0 | 40600.0 | 40000.0 | 40900.0 | 42300.0 | 42700.0 | 41600.0 | 46500.0 | 49700.0 |
44 rows × 28 columns
Videre ønsker vi å fjerne de definisjonene av EU vi ikke trenger, som er ‘EA18’,‘EA19’,‘EU27_2007’,‘EU27_2020’,‘EA18’ og ‘EA18’. Vi bruker samme teknikk, vi lager en liste som inneholder True og False, avhengig om en betingelse er oppfylt.
Feltet vi nå skal filtrere ut fra er “geo\time”, som innholder landkodene. Siden vi ikke bare skal sjekke om én streng er i denne kolonnen, men om flere mulige kandidater er det, kan vi ikke bruke “list comprehension” som over. Vi bruker i stedet en pandas-funksjon isin (is in), som tar en liste med “ting” vi ikke vil ha i feltet som argument.
unwanted=gdp_data['geo\\TIME_PERIOD'].isin(['EA18','EA19','EU27_2007','EU27_2020','EA18','EA18'])Men vi vil ikke ha unwanted, så vi tar kun med tilfellene der unwanted==False. I tillegg endrer vi kollonnenavnet for land til noe mer gjenkjennelig.
gdp_data_fltrd = gdp_data[unwanted==False]
gdp_data_fltrd = gdp_data_fltrd.rename(columns={'geo\\TIME_PERIOD':'country'})C:\Users\esi000\AppData\Local\Temp\ipykernel_25488\3512890155.py:1: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
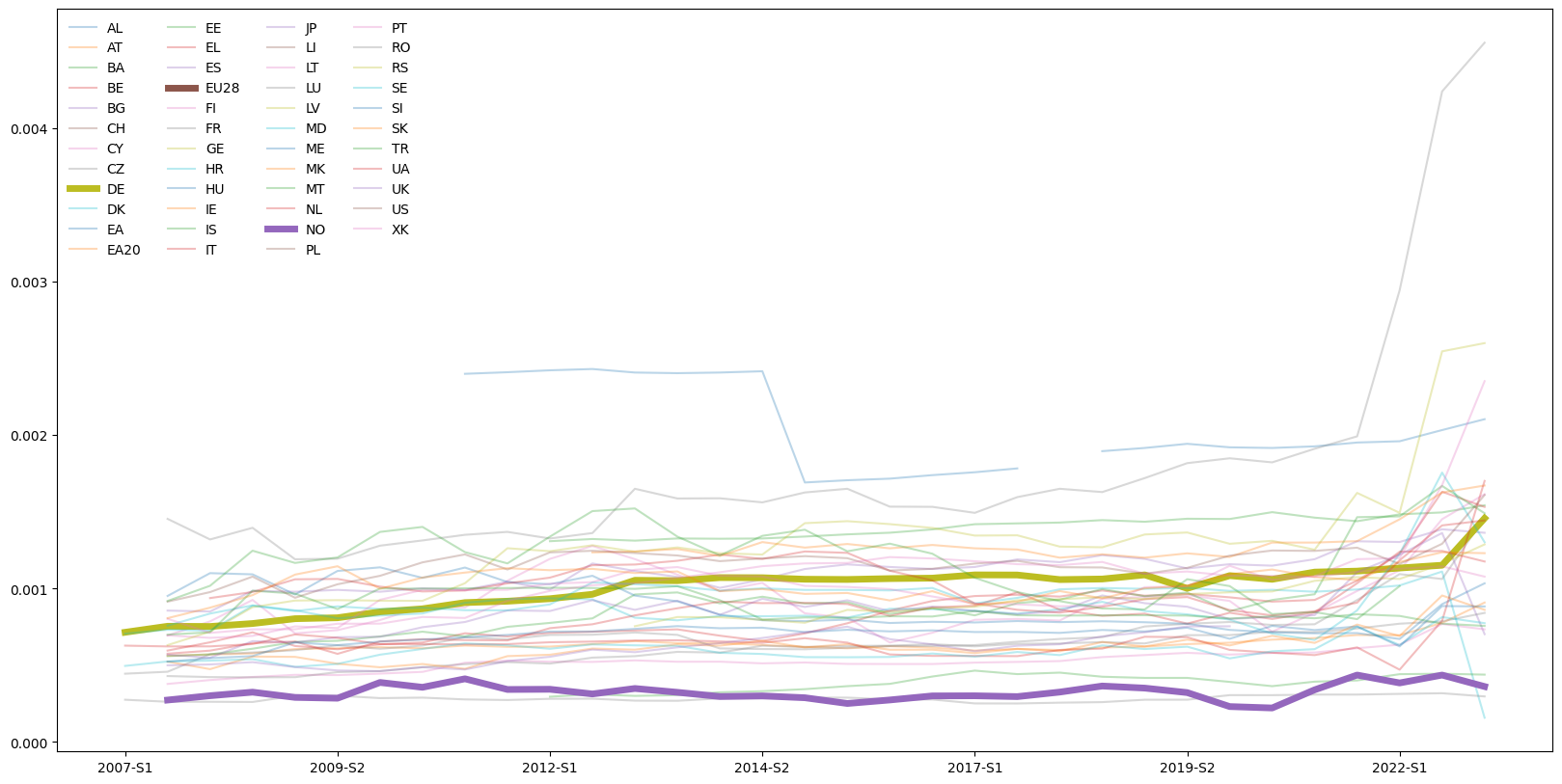
gdp_data_fltrd = gdp_data[unwanted==False]La oss se på utviklingen i BNP justert for kjøpekraft siden Angela Merkel tiltrådte som forbundskansler i 2005. Vi velger ut kolonnene 2005 til 2020, i tillegg til kolonnen ‘geo\time’ med landkodene, som skal stå først. Vi gjør det ved å lage en liste med de kolonnene vi ønsker å hente ut fra gdp_data. Vi lager da to lister som vi slår sammen:
Liste 1: Vi starter med navnet til første kolonne ‘geo\time’, som vi lager om til en liste med ett element ved hjelp av klammeparenteser: ['geo\\time'].
Liste 2: Vi bruker så den innebygde range() til å generere fra 2005 til 2020, og konverterer resultatet til en liste: list(range(2005,2021).
Summen av disse to listene blir da en liste med ‘geo\time’ først og så årstallene.
gdp_data_fltrd| freq | na_item | ppp_cat | unit | country | 2000 | 2001 | 2002 | 2003 | 2004 | ... | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | AL | 3200.0 | 3600.0 | 3800.0 | 4100.0 | 4400.0 | ... | 7600.0 | 8100.0 | 8400.0 | 8400.0 | 8800.0 | 9200.0 | 9500.0 | 9200.0 | 10300.0 | 12000.0 |
| 6 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | AT | 24400.0 | 24600.0 | 25600.0 | 26400.0 | 27600.0 | ... | 34600.0 | 35000.0 | 35900.0 | 36600.0 | 37200.0 | 38600.0 | 39400.0 | 37500.0 | 39800.0 | 44100.0 |
| 7 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | BA | NaN | NaN | NaN | NaN | NaN | ... | 8000.0 | 8100.0 | 8500.0 | 8900.0 | 9200.0 | 9800.0 | 10200.0 | 9900.0 | 11100.0 | 12500.0 |
| 8 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | BE | 23100.0 | 23800.0 | 24800.0 | 25400.0 | 26200.0 | ... | 31500.0 | 32200.0 | 33200.0 | 33800.0 | 34600.0 | 35600.0 | 36800.0 | 35700.0 | 39000.0 | 42200.0 |
| 9 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | BG | 5300.0 | 5800.0 | 6400.0 | 6900.0 | 7500.0 | ... | 12000.0 | 12600.0 | 13200.0 | 13900.0 | 14700.0 | 15600.0 | 16600.0 | 16600.0 | 18600.0 | 20700.0 |
| 10 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | CH | 30200.0 | 31000.0 | 31500.0 | 31600.0 | 32600.0 | ... | 44500.0 | 45400.0 | 46900.0 | 46800.0 | 46800.0 | 47900.0 | 47900.0 | 46400.0 | 50400.0 | 54300.0 |
| 11 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | CY | 17700.0 | 18900.0 | 19300.0 | 19900.0 | 21200.0 | ... | 22000.0 | 21600.0 | 22900.0 | 24900.0 | 26400.0 | 27600.0 | 29100.0 | 27100.0 | 29400.0 | 32300.0 |
| 12 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | CZ | 13500.0 | 14600.0 | 15000.0 | 16000.0 | 17100.0 | ... | 22200.0 | 23300.0 | 24400.0 | 25100.0 | 26700.0 | 27900.0 | 29200.0 | 28000.0 | 29700.0 | 32000.0 |
| 13 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | DE | 22800.0 | 23700.0 | 24200.0 | 24800.0 | 25900.0 | ... | 32500.0 | 33700.0 | 34200.0 | 35100.0 | 36500.0 | 37400.0 | 37900.0 | 37000.0 | 39000.0 | 41200.0 |
| 14 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | DK | 23800.0 | 24400.0 | 25100.0 | 25300.0 | 26900.0 | ... | 33700.0 | 34300.0 | 35300.0 | 36100.0 | 38000.0 | 39000.0 | 39500.0 | 39900.0 | 43000.0 | 48100.0 |
| 16 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EA20 | 20900.0 | 21800.0 | 22500.0 | 22900.0 | 23700.0 | ... | 28000.0 | 28500.0 | 29400.0 | 30200.0 | 31200.0 | 32100.0 | 33100.0 | 31500.0 | 33900.0 | 36600.0 |
| 17 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EE | 7800.0 | 8500.0 | 9500.0 | 10700.0 | 11800.0 | ... | 19800.0 | 20700.0 | 21000.0 | 21700.0 | 23300.0 | 24700.0 | 25800.0 | 25800.0 | 28800.0 | 30700.0 |
| 18 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EL | 16200.0 | 17300.0 | 18500.0 | 19600.0 | 20800.0 | ... | 18800.0 | 19100.0 | 19200.0 | 19100.0 | 19600.0 | 20100.0 | 20600.0 | 18600.0 | 20700.0 | 23900.0 |
| 19 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | ES | 17900.0 | 19000.0 | 20000.0 | 20600.0 | 21400.0 | ... | 23400.0 | 24000.0 | 25100.0 | 25900.0 | 27200.0 | 27600.0 | 28500.0 | 24900.0 | 27000.0 | 29800.0 |
| 22 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | EU28 | 18800.0 | 19700.0 | 20400.0 | 20900.0 | 21800.0 | ... | 26400.0 | 27000.0 | 27900.0 | 28500.0 | 29600.0 | 30500.0 | 31500.0 | 30000.0 | NaN | NaN |
| 23 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | FI | 22200.0 | 23000.0 | 23400.0 | 23800.0 | 25500.0 | ... | 29900.0 | 29900.0 | 30500.0 | 31200.0 | 32700.0 | 33600.0 | 34200.0 | 34300.0 | 36300.0 | 38400.0 |
| 24 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | FR | 21700.0 | 22800.0 | 23400.0 | 23100.0 | 23700.0 | ... | 28500.0 | 28800.0 | 29400.0 | 29800.0 | 30500.0 | 31400.0 | 33100.0 | 31400.0 | 33800.0 | 35800.0 |
| 25 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | HR | 8900.0 | 9600.0 | 10500.0 | 11200.0 | 12000.0 | ... | 16000.0 | 16000.0 | 16800.0 | 17600.0 | 18700.0 | 19600.0 | 20800.0 | 19500.0 | 22600.0 | 25700.0 |
| 26 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | HU | 9800.0 | 10900.0 | 11900.0 | 12700.0 | 13300.0 | ... | 17700.0 | 18400.0 | 19300.0 | 19400.0 | 20300.0 | 21600.0 | 22900.0 | 22400.0 | 24400.0 | 27300.0 |
| 27 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | IE | 25100.0 | 27000.0 | 28900.0 | 29800.0 | 31700.0 | ... | 34600.0 | 36700.0 | 49700.0 | 49800.0 | 53600.0 | 57500.0 | 59300.0 | 61600.0 | 70800.0 | 82100.0 |
| 28 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | IS | 24700.0 | 26400.0 | 26700.0 | 26900.0 | 29000.0 | ... | 32000.0 | 33000.0 | 35400.0 | 37200.0 | 38200.0 | 38800.0 | 39300.0 | 35600.0 | 38600.0 | 44900.0 |
| 29 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | IT | 22500.0 | 23200.0 | 23500.0 | 23900.0 | 24100.0 | ... | 26200.0 | 26100.0 | 26700.0 | 28000.0 | 28800.0 | 29400.0 | 30200.0 | 28300.0 | 30900.0 | 33700.0 |
| 30 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | JP | 22700.0 | 23100.0 | 23500.0 | 24100.0 | 25200.0 | ... | 28500.0 | 28300.0 | 29400.0 | 28200.0 | 28500.0 | 28700.0 | 28000.0 | 27400.0 | 28400.0 | 29700.0 |
| 31 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | LT | 7000.0 | 7800.0 | 8600.0 | 9900.0 | 10600.0 | ... | 19300.0 | 20200.0 | 20700.0 | 21500.0 | 23200.0 | 24700.0 | 26400.0 | 26300.0 | 29000.0 | 31500.0 |
| 32 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | LU | 45700.0 | 46400.0 | 48000.0 | 49300.0 | 52800.0 | ... | 72600.0 | 75200.0 | 77600.0 | 78500.0 | 78900.0 | 78900.0 | 78700.0 | 78500.0 | 87000.0 | 91900.0 |
| 33 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | LV | 6700.0 | 7500.0 | 8300.0 | 9100.0 | 10000.0 | ... | 16300.0 | 17100.0 | 18000.0 | 18600.0 | 19700.0 | 20900.0 | 21700.0 | 21600.0 | 23300.0 | 25900.0 |
| 34 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | ME | NaN | NaN | NaN | NaN | NaN | ... | 10700.0 | 11000.0 | 11700.0 | 12600.0 | 13500.0 | 14600.0 | 15700.0 | 13400.0 | 15500.0 | 17500.0 |
| 35 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | MK | 5100.0 | 5000.0 | 5200.0 | 5400.0 | 5900.0 | ... | 9200.0 | 9600.0 | 10000.0 | 10500.0 | 10800.0 | 11400.0 | 11900.0 | 11300.0 | 13700.0 | 14700.0 |
| 36 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | MT | 15300.0 | 15300.0 | 16100.0 | 17200.0 | 17600.0 | ... | 23300.0 | 24600.0 | 26900.0 | 27600.0 | 29800.0 | 30900.0 | 32400.0 | 29400.0 | 33100.0 | 36000.0 |
| 37 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | NL | 26500.0 | 27500.0 | 28200.0 | 28000.0 | 29300.0 | ... | 35500.0 | 35300.0 | 36200.0 | 36300.0 | 37800.0 | 39200.0 | 39700.0 | 39200.0 | 42000.0 | 45300.0 |
| 38 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | NO | 30700.0 | 31300.0 | 31200.0 | 31800.0 | 34900.0 | ... | 48600.0 | 47500.0 | 43700.0 | 41200.0 | 44400.0 | 47600.0 | 46100.0 | 42700.0 | 54300.0 | 74800.0 |
| 39 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | PL | 8900.0 | 9200.0 | 9700.0 | 10100.0 | 10900.0 | ... | 17300.0 | 17900.0 | 19000.0 | 19300.0 | 20300.0 | 21500.0 | 22800.0 | 22900.0 | 25100.0 | 28000.0 |
| 40 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | PT | 15700.0 | 16200.0 | 16700.0 | 17100.0 | 17500.0 | ... | 20200.0 | 20600.0 | 21300.0 | 22000.0 | 22700.0 | 23700.0 | 24600.0 | 22900.0 | 24400.0 | 27200.0 |
| 41 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | RO | 4900.0 | 5300.0 | 5900.0 | 6200.0 | 7300.0 | ... | 14200.0 | 14800.0 | 15500.0 | 16600.0 | 18500.0 | 20000.0 | 21800.0 | 21800.0 | 24000.0 | 27100.0 |
| 42 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | RS | 5000.0 | 5400.0 | 5900.0 | 6300.0 | 6900.0 | ... | 10600.0 | 10500.0 | 10700.0 | 11000.0 | 11400.0 | 12000.0 | 12800.0 | 12800.0 | 14300.0 | 15500.0 |
| 43 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | SE | 24600.0 | 24800.0 | 25300.0 | 26100.0 | 27700.0 | ... | 33400.0 | 33800.0 | 35300.0 | 35000.0 | 35700.0 | 36300.0 | 37200.0 | 36800.0 | 40000.0 | 42300.0 |
| 44 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | SI | 14900.0 | 15700.0 | 16600.0 | 17300.0 | 18600.0 | ... | 21600.0 | 22100.0 | 22700.0 | 23600.0 | 25100.0 | 26500.0 | 27800.0 | 26800.0 | 29200.0 | 32500.0 |
| 45 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | SK | 9400.0 | 10300.0 | 10900.0 | 11600.0 | 12400.0 | ... | 20200.0 | 20800.0 | 21600.0 | 20700.0 | 20700.0 | 21300.0 | 22100.0 | 21600.0 | 22900.0 | 24100.0 |
| 46 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | TR | 7900.0 | 7600.0 | 7600.0 | 7900.0 | 8900.0 | ... | 16100.0 | 17300.0 | 18600.0 | 18500.0 | 19400.0 | 19200.0 | 18500.0 | 18300.0 | 20300.0 | 24300.0 |
| 47 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | UK | 22000.0 | 23100.0 | 23800.0 | 24900.0 | 26200.0 | ... | 28900.0 | 29600.0 | 30600.0 | 30700.0 | 31700.0 | 32000.0 | 32500.0 | 30000.0 | 32900.0 | 35100.0 |
| 48 | A | EXP_PPS_EU27_2020_HAB | GDP | PC | US | 30100.0 | 30700.0 | 31100.0 | 32400.0 | 34000.0 | ... | 38300.0 | 39400.0 | 40600.0 | 40000.0 | 40900.0 | 42300.0 | 42700.0 | 41600.0 | 46500.0 | 49700.0 |
41 rows × 28 columns
chosen_columns=['country']+[str(i) for i in range(2005,2021)]
chosen_columns['country',
'2005',
'2006',
'2007',
'2008',
'2009',
'2010',
'2011',
'2012',
'2013',
'2014',
'2015',
'2016',
'2017',
'2018',
'2019',
'2020']Vi kan nå velge ut kun disse kolonnene ved å velge samtlige rader fra gdp_data.loc, og kolonnene angitt av listen:
gdp_data_fltrd2 = gdp_data_fltrd[chosen_columns]Så ønsker vi videre å kategorisere observasjonene ut fra landkode, og ikke rekkefølge. Vi setter derfor ‘geo\time’ som indeks:
gdp_data_fltrd2=gdp_data_fltrd2.set_index('country')
gdp_data_fltrd2| 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| country | ||||||||||||||||
| AL | 4800.0 | 5200.0 | 5800.0 | 6400.0 | 6700.0 | 7300.0 | 7600.0 | 7800.0 | 7600.0 | 8100.0 | 8400.0 | 8400.0 | 8800.0 | 9200.0 | 9500.0 | 9200.0 |
| AT | 28700.0 | 29900.0 | 31100.0 | 32100.0 | 30900.0 | 31800.0 | 33100.0 | 34300.0 | 34600.0 | 35000.0 | 35900.0 | 36600.0 | 37200.0 | 38600.0 | 39400.0 | 37500.0 |
| BA | 5600.0 | 6300.0 | 6900.0 | 7400.0 | 7200.0 | 7400.0 | 7700.0 | 7800.0 | 8000.0 | 8100.0 | 8500.0 | 8900.0 | 9200.0 | 9800.0 | 10200.0 | 9900.0 |
| BE | 27200.0 | 28000.0 | 29000.0 | 29400.0 | 28500.0 | 30100.0 | 30500.0 | 31200.0 | 31500.0 | 32200.0 | 33200.0 | 33800.0 | 34600.0 | 35600.0 | 36800.0 | 35700.0 |
| BG | 8300.0 | 9000.0 | 10000.0 | 10900.0 | 10500.0 | 11100.0 | 11700.0 | 12100.0 | 12000.0 | 12600.0 | 13200.0 | 13900.0 | 14700.0 | 15600.0 | 16600.0 | 16600.0 |
| CH | 33800.0 | 36500.0 | 39900.0 | 41500.0 | 39800.0 | 41100.0 | 42800.0 | 43900.0 | 44500.0 | 45400.0 | 46900.0 | 46800.0 | 46800.0 | 47900.0 | 47900.0 | 46400.0 |
| CY | 22700.0 | 23900.0 | 26000.0 | 27000.0 | 25600.0 | 25400.0 | 24900.0 | 23600.0 | 22000.0 | 21600.0 | 22900.0 | 24900.0 | 26400.0 | 27600.0 | 29100.0 | 27100.0 |
| CZ | 18100.0 | 19000.0 | 20700.0 | 21600.0 | 20900.0 | 21000.0 | 21600.0 | 21600.0 | 22200.0 | 23300.0 | 24400.0 | 25100.0 | 26700.0 | 27900.0 | 29200.0 | 28000.0 |
| DE | 26400.0 | 27600.0 | 29100.0 | 29800.0 | 28300.0 | 30000.0 | 31700.0 | 32000.0 | 32500.0 | 33700.0 | 34200.0 | 35100.0 | 36500.0 | 37400.0 | 37900.0 | 37000.0 |
| DK | 28000.0 | 29700.0 | 30800.0 | 32000.0 | 30500.0 | 32500.0 | 33100.0 | 33100.0 | 33700.0 | 34300.0 | 35300.0 | 36100.0 | 38000.0 | 39000.0 | 39500.0 | 39900.0 |
| EA20 | 24600.0 | 25800.0 | 27100.0 | 27700.0 | 26200.0 | 27000.0 | 27700.0 | 27700.0 | 28000.0 | 28500.0 | 29400.0 | 30200.0 | 31200.0 | 32100.0 | 33100.0 | 31500.0 |
| EE | 13600.0 | 15300.0 | 17500.0 | 17700.0 | 15400.0 | 16300.0 | 18300.0 | 19200.0 | 19800.0 | 20700.0 | 21000.0 | 21700.0 | 23300.0 | 24700.0 | 25800.0 | 25800.0 |
| EL | 20900.0 | 22700.0 | 23100.0 | 23900.0 | 22900.0 | 21100.0 | 19100.0 | 18400.0 | 18800.0 | 19100.0 | 19200.0 | 19100.0 | 19600.0 | 20100.0 | 20600.0 | 18600.0 |
| ES | 22600.0 | 24400.0 | 25600.0 | 25800.0 | 24200.0 | 24000.0 | 23700.0 | 23400.0 | 23400.0 | 24000.0 | 25100.0 | 25900.0 | 27200.0 | 27600.0 | 28500.0 | 24900.0 |
| EU28 | 22600.0 | 23800.0 | 25000.0 | 25700.0 | 24400.0 | 25300.0 | 25900.0 | 26100.0 | 26400.0 | 27000.0 | 27900.0 | 28500.0 | 29600.0 | 30500.0 | 31500.0 | 30000.0 |
| FI | 26200.0 | 27400.0 | 29900.0 | 31100.0 | 28700.0 | 29500.0 | 30500.0 | 30200.0 | 29900.0 | 29900.0 | 30500.0 | 31200.0 | 32700.0 | 33600.0 | 34200.0 | 34300.0 |
| FR | 25000.0 | 25800.0 | 26900.0 | 27200.0 | 26200.0 | 27200.0 | 27900.0 | 27800.0 | 28500.0 | 28800.0 | 29400.0 | 29800.0 | 30500.0 | 31400.0 | 33100.0 | 31400.0 |
| HR | 12700.0 | 14000.0 | 15400.0 | 16300.0 | 15300.0 | 15200.0 | 15700.0 | 15800.0 | 16000.0 | 16000.0 | 16800.0 | 17600.0 | 18700.0 | 19600.0 | 20800.0 | 19500.0 |
| HU | 14000.0 | 14600.0 | 15100.0 | 16100.0 | 15600.0 | 16500.0 | 17200.0 | 17200.0 | 17700.0 | 18400.0 | 19300.0 | 19400.0 | 20300.0 | 21600.0 | 22900.0 | 22400.0 |
| IE | 33100.0 | 35200.0 | 36900.0 | 34200.0 | 31300.0 | 32700.0 | 33600.0 | 34300.0 | 34600.0 | 36700.0 | 49700.0 | 49800.0 | 53600.0 | 57500.0 | 59300.0 | 61600.0 |
| IS | 30600.0 | 31500.0 | 32800.0 | 33700.0 | 31500.0 | 30100.0 | 30500.0 | 31000.0 | 32000.0 | 33000.0 | 35400.0 | 37200.0 | 38200.0 | 38800.0 | 39300.0 | 35600.0 |
| IT | 24600.0 | 25700.0 | 26800.0 | 27400.0 | 25900.0 | 26400.0 | 27000.0 | 26600.0 | 26200.0 | 26100.0 | 26700.0 | 28000.0 | 28800.0 | 29400.0 | 30200.0 | 28300.0 |
| JP | 26300.0 | 26700.0 | 27600.0 | 27400.0 | 25300.0 | 26700.0 | 27000.0 | 27800.0 | 28500.0 | 28300.0 | 29400.0 | 28200.0 | 28500.0 | 28700.0 | 28000.0 | 27400.0 |
| LT | 11900.0 | 13100.0 | 15100.0 | 16100.0 | 13700.0 | 15200.0 | 17100.0 | 18200.0 | 19300.0 | 20200.0 | 20700.0 | 21500.0 | 23200.0 | 24700.0 | 26400.0 | 26300.0 |
| LU | 56300.0 | 62700.0 | 67100.0 | 70500.0 | 65500.0 | 68300.0 | 70200.0 | 71300.0 | 72600.0 | 75200.0 | 77600.0 | 78500.0 | 78900.0 | 78900.0 | 78700.0 | 78500.0 |
| LV | 11400.0 | 12600.0 | 14400.0 | 15200.0 | 12900.0 | 13400.0 | 14300.0 | 15700.0 | 16300.0 | 17100.0 | 18000.0 | 18600.0 | 19700.0 | 20900.0 | 21700.0 | 21600.0 |
| ME | NaN | 8300.0 | 9800.0 | 10700.0 | 9800.0 | 10300.0 | 10800.0 | 10200.0 | 10700.0 | 11000.0 | 11700.0 | 12600.0 | 13500.0 | 14600.0 | 15700.0 | 13400.0 |
| MK | 6400.0 | 6900.0 | 7400.0 | 8200.0 | 8300.0 | 8600.0 | 8700.0 | 8800.0 | 9200.0 | 9600.0 | 10000.0 | 10500.0 | 10800.0 | 11400.0 | 11900.0 | 11300.0 |
| MT | 18300.0 | 18500.0 | 19800.0 | 20600.0 | 20100.0 | 21700.0 | 21600.0 | 22300.0 | 23300.0 | 24600.0 | 26900.0 | 27600.0 | 29800.0 | 30900.0 | 32400.0 | 29400.0 |
| NL | 30800.0 | 32600.0 | 34700.0 | 36000.0 | 33600.0 | 34100.0 | 34700.0 | 34900.0 | 35500.0 | 35300.0 | 36200.0 | 36300.0 | 37800.0 | 39200.0 | 39700.0 | 39200.0 |
| NO | 39300.0 | 43200.0 | 44300.0 | 48200.0 | 42000.0 | 44100.0 | 46500.0 | 48600.0 | 48600.0 | 47500.0 | 43700.0 | 41200.0 | 44400.0 | 47600.0 | 46100.0 | 42700.0 |
| PL | 11400.0 | 12000.0 | 13300.0 | 14200.0 | 14400.0 | 15600.0 | 16700.0 | 17200.0 | 17300.0 | 17900.0 | 19000.0 | 19300.0 | 20300.0 | 21500.0 | 22800.0 | 22900.0 |
| PT | 18600.0 | 19600.0 | 20300.0 | 20700.0 | 20000.0 | 20600.0 | 19900.0 | 19500.0 | 20200.0 | 20600.0 | 21300.0 | 22000.0 | 22700.0 | 23700.0 | 24600.0 | 22900.0 |
| RO | 7900.0 | 9200.0 | 10800.0 | 13000.0 | 12600.0 | 13100.0 | 14000.0 | 14600.0 | 14200.0 | 14800.0 | 15500.0 | 16600.0 | 18500.0 | 20000.0 | 21800.0 | 21800.0 |
| RS | 7500.0 | 8100.0 | 8900.0 | 9800.0 | 9500.0 | 9700.0 | 10200.0 | 10300.0 | 10600.0 | 10500.0 | 10700.0 | 11000.0 | 11400.0 | 12000.0 | 12800.0 | 12800.0 |
| SE | 28000.0 | 30000.0 | 32300.0 | 32700.0 | 30400.0 | 32000.0 | 33200.0 | 33500.0 | 33400.0 | 33800.0 | 35300.0 | 35000.0 | 35700.0 | 36300.0 | 37200.0 | 36800.0 |
| SI | 19500.0 | 20400.0 | 21800.0 | 23000.0 | 20800.0 | 21100.0 | 21600.0 | 21400.0 | 21600.0 | 22100.0 | 22700.0 | 23600.0 | 25100.0 | 26500.0 | 27800.0 | 26800.0 |
| SK | 13600.0 | 15000.0 | 16700.0 | 18300.0 | 17300.0 | 19100.0 | 19600.0 | 19900.0 | 20200.0 | 20800.0 | 21600.0 | 20700.0 | 20700.0 | 21300.0 | 22100.0 | 21600.0 |
| TR | 9800.0 | 10800.0 | 11700.0 | 12400.0 | 11700.0 | 13100.0 | 14600.0 | 15200.0 | 16100.0 | 17300.0 | 18600.0 | 18500.0 | 19400.0 | 19200.0 | 18500.0 | 18300.0 |
| UK | 26800.0 | 27600.0 | 28100.0 | 28500.0 | 26500.0 | 27700.0 | 27800.0 | 28300.0 | 28900.0 | 29600.0 | 30600.0 | 30700.0 | 31700.0 | 32000.0 | 32500.0 | 30000.0 |
| US | 36100.0 | 36800.0 | 37900.0 | 37600.0 | 35600.0 | 36800.0 | 37200.0 | 38100.0 | 38300.0 | 39400.0 | 40600.0 | 40000.0 | 40900.0 | 42300.0 | 42700.0 | 41600.0 |
Vi skal nå “rebasere” tallene slik at alle starter på 100. Vi må først sørge for at hvert årstall er en observasjon/rad, og ikke en kolonne. Vi gjør det med pandasfunksjonen transpose(). Den bytter om på rader og kolonner:
gdp_data_fltrd3=gdp_data_fltrd2.transpose()
gdp_data_fltrd3| country | AL | AT | BA | BE | BG | CH | CY | CZ | DE | DK | ... | PL | PT | RO | RS | SE | SI | SK | TR | UK | US |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2005 | 4800.0 | 28700.0 | 5600.0 | 27200.0 | 8300.0 | 33800.0 | 22700.0 | 18100.0 | 26400.0 | 28000.0 | ... | 11400.0 | 18600.0 | 7900.0 | 7500.0 | 28000.0 | 19500.0 | 13600.0 | 9800.0 | 26800.0 | 36100.0 |
| 2006 | 5200.0 | 29900.0 | 6300.0 | 28000.0 | 9000.0 | 36500.0 | 23900.0 | 19000.0 | 27600.0 | 29700.0 | ... | 12000.0 | 19600.0 | 9200.0 | 8100.0 | 30000.0 | 20400.0 | 15000.0 | 10800.0 | 27600.0 | 36800.0 |
| 2007 | 5800.0 | 31100.0 | 6900.0 | 29000.0 | 10000.0 | 39900.0 | 26000.0 | 20700.0 | 29100.0 | 30800.0 | ... | 13300.0 | 20300.0 | 10800.0 | 8900.0 | 32300.0 | 21800.0 | 16700.0 | 11700.0 | 28100.0 | 37900.0 |
| 2008 | 6400.0 | 32100.0 | 7400.0 | 29400.0 | 10900.0 | 41500.0 | 27000.0 | 21600.0 | 29800.0 | 32000.0 | ... | 14200.0 | 20700.0 | 13000.0 | 9800.0 | 32700.0 | 23000.0 | 18300.0 | 12400.0 | 28500.0 | 37600.0 |
| 2009 | 6700.0 | 30900.0 | 7200.0 | 28500.0 | 10500.0 | 39800.0 | 25600.0 | 20900.0 | 28300.0 | 30500.0 | ... | 14400.0 | 20000.0 | 12600.0 | 9500.0 | 30400.0 | 20800.0 | 17300.0 | 11700.0 | 26500.0 | 35600.0 |
| 2010 | 7300.0 | 31800.0 | 7400.0 | 30100.0 | 11100.0 | 41100.0 | 25400.0 | 21000.0 | 30000.0 | 32500.0 | ... | 15600.0 | 20600.0 | 13100.0 | 9700.0 | 32000.0 | 21100.0 | 19100.0 | 13100.0 | 27700.0 | 36800.0 |
| 2011 | 7600.0 | 33100.0 | 7700.0 | 30500.0 | 11700.0 | 42800.0 | 24900.0 | 21600.0 | 31700.0 | 33100.0 | ... | 16700.0 | 19900.0 | 14000.0 | 10200.0 | 33200.0 | 21600.0 | 19600.0 | 14600.0 | 27800.0 | 37200.0 |
| 2012 | 7800.0 | 34300.0 | 7800.0 | 31200.0 | 12100.0 | 43900.0 | 23600.0 | 21600.0 | 32000.0 | 33100.0 | ... | 17200.0 | 19500.0 | 14600.0 | 10300.0 | 33500.0 | 21400.0 | 19900.0 | 15200.0 | 28300.0 | 38100.0 |
| 2013 | 7600.0 | 34600.0 | 8000.0 | 31500.0 | 12000.0 | 44500.0 | 22000.0 | 22200.0 | 32500.0 | 33700.0 | ... | 17300.0 | 20200.0 | 14200.0 | 10600.0 | 33400.0 | 21600.0 | 20200.0 | 16100.0 | 28900.0 | 38300.0 |
| 2014 | 8100.0 | 35000.0 | 8100.0 | 32200.0 | 12600.0 | 45400.0 | 21600.0 | 23300.0 | 33700.0 | 34300.0 | ... | 17900.0 | 20600.0 | 14800.0 | 10500.0 | 33800.0 | 22100.0 | 20800.0 | 17300.0 | 29600.0 | 39400.0 |
| 2015 | 8400.0 | 35900.0 | 8500.0 | 33200.0 | 13200.0 | 46900.0 | 22900.0 | 24400.0 | 34200.0 | 35300.0 | ... | 19000.0 | 21300.0 | 15500.0 | 10700.0 | 35300.0 | 22700.0 | 21600.0 | 18600.0 | 30600.0 | 40600.0 |
| 2016 | 8400.0 | 36600.0 | 8900.0 | 33800.0 | 13900.0 | 46800.0 | 24900.0 | 25100.0 | 35100.0 | 36100.0 | ... | 19300.0 | 22000.0 | 16600.0 | 11000.0 | 35000.0 | 23600.0 | 20700.0 | 18500.0 | 30700.0 | 40000.0 |
| 2017 | 8800.0 | 37200.0 | 9200.0 | 34600.0 | 14700.0 | 46800.0 | 26400.0 | 26700.0 | 36500.0 | 38000.0 | ... | 20300.0 | 22700.0 | 18500.0 | 11400.0 | 35700.0 | 25100.0 | 20700.0 | 19400.0 | 31700.0 | 40900.0 |
| 2018 | 9200.0 | 38600.0 | 9800.0 | 35600.0 | 15600.0 | 47900.0 | 27600.0 | 27900.0 | 37400.0 | 39000.0 | ... | 21500.0 | 23700.0 | 20000.0 | 12000.0 | 36300.0 | 26500.0 | 21300.0 | 19200.0 | 32000.0 | 42300.0 |
| 2019 | 9500.0 | 39400.0 | 10200.0 | 36800.0 | 16600.0 | 47900.0 | 29100.0 | 29200.0 | 37900.0 | 39500.0 | ... | 22800.0 | 24600.0 | 21800.0 | 12800.0 | 37200.0 | 27800.0 | 22100.0 | 18500.0 | 32500.0 | 42700.0 |
| 2020 | 9200.0 | 37500.0 | 9900.0 | 35700.0 | 16600.0 | 46400.0 | 27100.0 | 28000.0 | 37000.0 | 39900.0 | ... | 22900.0 | 22900.0 | 21800.0 | 12800.0 | 36800.0 | 26800.0 | 21600.0 | 18300.0 | 30000.0 | 41600.0 |
16 rows × 41 columns
Vi kan nå “rebasere”. Vi gjør det ved å bruke pandasfunksjonen div(), som deler alle observasjonene på argumentet. Vi ønsker å dele på første rad (år 2005), som er gdp_data.iloc[0]:
gdp_data_fltrd4=100*gdp_data_fltrd3.div(gdp_data_fltrd3.iloc[0])
gdp_data_fltrd4| country | AL | AT | BA | BE | BG | CH | CY | CZ | DE | DK | ... | PL | PT | RO | RS | SE | SI | SK | TR | UK | US |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2005 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | ... | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 | 100.000000 |
| 2006 | 108.333333 | 104.181185 | 112.500000 | 102.941176 | 108.433735 | 107.988166 | 105.286344 | 104.972376 | 104.545455 | 106.071429 | ... | 105.263158 | 105.376344 | 116.455696 | 108.000000 | 107.142857 | 104.615385 | 110.294118 | 110.204082 | 102.985075 | 101.939058 |
| 2007 | 120.833333 | 108.362369 | 123.214286 | 106.617647 | 120.481928 | 118.047337 | 114.537445 | 114.364641 | 110.227273 | 110.000000 | ... | 116.666667 | 109.139785 | 136.708861 | 118.666667 | 115.357143 | 111.794872 | 122.794118 | 119.387755 | 104.850746 | 104.986150 |
| 2008 | 133.333333 | 111.846690 | 132.142857 | 108.088235 | 131.325301 | 122.781065 | 118.942731 | 119.337017 | 112.878788 | 114.285714 | ... | 124.561404 | 111.290323 | 164.556962 | 130.666667 | 116.785714 | 117.948718 | 134.558824 | 126.530612 | 106.343284 | 104.155125 |
| 2009 | 139.583333 | 107.665505 | 128.571429 | 104.779412 | 126.506024 | 117.751479 | 112.775330 | 115.469613 | 107.196970 | 108.928571 | ... | 126.315789 | 107.526882 | 159.493671 | 126.666667 | 108.571429 | 106.666667 | 127.205882 | 119.387755 | 98.880597 | 98.614958 |
| 2010 | 152.083333 | 110.801394 | 132.142857 | 110.661765 | 133.734940 | 121.597633 | 111.894273 | 116.022099 | 113.636364 | 116.071429 | ... | 136.842105 | 110.752688 | 165.822785 | 129.333333 | 114.285714 | 108.205128 | 140.441176 | 133.673469 | 103.358209 | 101.939058 |
| 2011 | 158.333333 | 115.331010 | 137.500000 | 112.132353 | 140.963855 | 126.627219 | 109.691630 | 119.337017 | 120.075758 | 118.214286 | ... | 146.491228 | 106.989247 | 177.215190 | 136.000000 | 118.571429 | 110.769231 | 144.117647 | 148.979592 | 103.731343 | 103.047091 |
| 2012 | 162.500000 | 119.512195 | 139.285714 | 114.705882 | 145.783133 | 129.881657 | 103.964758 | 119.337017 | 121.212121 | 118.214286 | ... | 150.877193 | 104.838710 | 184.810127 | 137.333333 | 119.642857 | 109.743590 | 146.323529 | 155.102041 | 105.597015 | 105.540166 |
| 2013 | 158.333333 | 120.557491 | 142.857143 | 115.808824 | 144.578313 | 131.656805 | 96.916300 | 122.651934 | 123.106061 | 120.357143 | ... | 151.754386 | 108.602151 | 179.746835 | 141.333333 | 119.285714 | 110.769231 | 148.529412 | 164.285714 | 107.835821 | 106.094183 |
| 2014 | 168.750000 | 121.951220 | 144.642857 | 118.382353 | 151.807229 | 134.319527 | 95.154185 | 128.729282 | 127.651515 | 122.500000 | ... | 157.017544 | 110.752688 | 187.341772 | 140.000000 | 120.714286 | 113.333333 | 152.941176 | 176.530612 | 110.447761 | 109.141274 |
| 2015 | 175.000000 | 125.087108 | 151.785714 | 122.058824 | 159.036145 | 138.757396 | 100.881057 | 134.806630 | 129.545455 | 126.071429 | ... | 166.666667 | 114.516129 | 196.202532 | 142.666667 | 126.071429 | 116.410256 | 158.823529 | 189.795918 | 114.179104 | 112.465374 |
| 2016 | 175.000000 | 127.526132 | 158.928571 | 124.264706 | 167.469880 | 138.461538 | 109.691630 | 138.674033 | 132.954545 | 128.928571 | ... | 169.298246 | 118.279570 | 210.126582 | 146.666667 | 125.000000 | 121.025641 | 152.205882 | 188.775510 | 114.552239 | 110.803324 |
| 2017 | 183.333333 | 129.616725 | 164.285714 | 127.205882 | 177.108434 | 138.461538 | 116.299559 | 147.513812 | 138.257576 | 135.714286 | ... | 178.070175 | 122.043011 | 234.177215 | 152.000000 | 127.500000 | 128.717949 | 152.205882 | 197.959184 | 118.283582 | 113.296399 |
| 2018 | 191.666667 | 134.494774 | 175.000000 | 130.882353 | 187.951807 | 141.715976 | 121.585903 | 154.143646 | 141.666667 | 139.285714 | ... | 188.596491 | 127.419355 | 253.164557 | 160.000000 | 129.642857 | 135.897436 | 156.617647 | 195.918367 | 119.402985 | 117.174515 |
| 2019 | 197.916667 | 137.282230 | 182.142857 | 135.294118 | 200.000000 | 141.715976 | 128.193833 | 161.325967 | 143.560606 | 141.071429 | ... | 200.000000 | 132.258065 | 275.949367 | 170.666667 | 132.857143 | 142.564103 | 162.500000 | 188.775510 | 121.268657 | 118.282548 |
| 2020 | 191.666667 | 130.662021 | 176.785714 | 131.250000 | 200.000000 | 137.278107 | 119.383260 | 154.696133 | 140.151515 | 142.500000 | ... | 200.877193 | 123.118280 | 275.949367 | 170.666667 | 131.428571 | 137.435897 | 158.823529 | 186.734694 | 111.940299 | 115.235457 |
16 rows × 41 columns
Vi kan nå plotte resultatet med plot()-funksjonen i pandas. Vi velger gjennomsiktighet 0.3 og figurstørrelse 20x10. Etikettene plasseres øverst til venstre, uten ramme og i fire kolonner:
ax=gdp_data_fltrd4.plot(alpha=0.3,figsize=(20, 10))
ax.legend(loc='upper left',frameon=False,ncol=4)<matplotlib.legend.Legend at 0x1843373ced0>
Som nevnt har vi valgt perioden fra 2005 fordi Angela Merkel tiltrådte da. Det kan derfor være en god idé å utheve Tysklands kurve. Vi skal gjøre det ved å øke linjevidden til 5 og ta bort gjennomsiktighet (alpha=1). For at det skal være enkelt å også utheve andre land, lager vi en funksjon som uthever land med et bestemt symbol. ax representerer grafen, og må også være et argument, slik at funksjonen kan operere på den. Her er funksjonen:
def thick_line(symbol,ax):
labels=[i._label for i in ax.lines] #makes a list of symbols in the order of lines in the axis object
i=labels.index(symbol) #identifies at which position symbol is located
ax.lines[i].set_linewidth(5) #sets the line with of the line at position i to 5
ax.lines[i].set_alpha(1) #removes transparancy of the line at position i to 5 Funksjonen gjør følgende: 1. Lager en liste med symbolene til linjene 2. identifiserer hvor i listen symbol befinner seg 3. setter linjevidden til denne linjen til 5 4. Fjerner gjennomsiktigheten til denne linjen
Vi kan nå plotte grafen, etter å ha uthevet linjene til ‘DE’ (Tyskland) ‘NO’ (Norge) og ‘EU28’ (EU inkludert Storbritannia):
thick_line('DE',ax)
thick_line('NO',ax)
thick_line('EU28',ax)
ax.legend(loc='upper left',frameon=False,ncol=4)
ax.figure
scatter()-funksjonen for å se om det er en sammenheng mellom avkastningene.sql=("SELECT distinct Name,date, lnDeltaP FROM equity "
"WHERE (Name='Sbanken' OR Name='Aker BP' ) "
"AND `Date`>'2000-01-01'"
"ORDER BY `Date`")
df=pd.read_sql_query(sql, con)
df=df.pivot(index='date', columns='Name', values='lnDeltaP')
df.plot.scatter('Aker BP', 'Sbanken')C:\Users\esi000\AppData\Local\Temp\ipykernel_25488\3797233693.py:6: UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.
df=pd.read_sql_query(sql, con)<AxesSubplot: xlabel='Aker BP', ylabel='Sbanken'>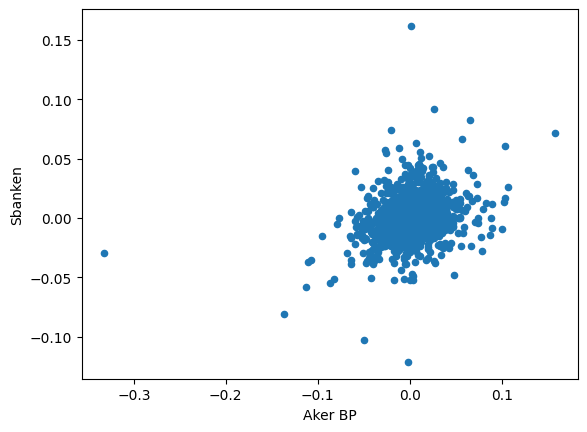
animal. Hvorfor?cats er lagt til mamals, så det er umulgi for noe dyr å ikke være i cats men samtidig være i mamals. Derfor er den andre elif-setningen aldri tilfredstilt.
or edu>10 fra koden? Forklar.or edu>10 tas også BNP_per_capita under 20 000 med, dersom utdannelse er over 10sql=("SELECT distinct Name,date, mktcap,PE,LIQ from equity "
"WHERE (Name='Biotec Pharmacon' ) "
"AND `Date`>'2000-01-01'"
"ORDER BY `Date`")
df=pd.read_sql_query(sql, con)
df['lmktcap'] = np.log(df['mktcap'])
df['10*LIQ'] = 300*df['LIQ']
df.plot('date',['lmktcap','PE','10*LIQ'] , ylim=(-100, 30) )
dfC:\Users\esi000\AppData\Local\Temp\ipykernel_25488\1810833590.py:6: UserWarning: pandas only supports SQLAlchemy connectable (engine/connection) or database string URI or sqlite3 DBAPI2 connection. Other DBAPI2 objects are not tested. Please consider using SQLAlchemy.
df=pd.read_sql_query(sql, con)| Name | date | mktcap | PE | LIQ | lmktcap | 10*LIQ | |
|---|---|---|---|---|---|---|---|
| 0 | Biotec Pharmacon | 2005-11-04 | 5.372250e+08 | -78.8761 | -0.006871 | 20.101928 | -2.061216 |
| 1 | Biotec Pharmacon | 2005-11-07 | 5.049920e+08 | -74.1436 | 0.006790 | 20.040053 | 2.037036 |
| 2 | Biotec Pharmacon | 2005-11-08 | 4.684600e+08 | -68.7800 | -0.004358 | 19.964961 | -1.307466 |
| 3 | Biotec Pharmacon | 2005-11-09 | 4.792050e+08 | -70.3575 | 0.013341 | 19.987639 | 4.002450 |
| 4 | Biotec Pharmacon | 2005-11-10 | 4.942470e+08 | -72.5660 | -0.001847 | 20.018546 | -0.554190 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3635 | Biotec Pharmacon | 2020-11-23 | 3.373760e+09 | -445.3220 | -0.000805 | 21.939294 | -0.241403 |
| 3636 | Biotec Pharmacon | 2020-11-24 | 3.132090e+09 | -413.4220 | 0.004827 | 21.864966 | 1.448235 |
| 3637 | Biotec Pharmacon | 2020-11-25 | 3.306090e+09 | -436.3900 | 0.010409 | 21.919032 | 3.122580 |
| 3638 | Biotec Pharmacon | 2020-11-26 | 3.267420e+09 | -431.2860 | -0.018074 | 21.907267 | -5.422260 |
| 3639 | Biotec Pharmacon | 2020-11-27 | 3.325430e+09 | -438.9420 | -0.011508 | 21.924865 | -3.452370 |
3640 rows × 7 columns
toc[['Electricity' in i for i in toc['title']]] og finn koden i feltet ‘code’ til tabellen ‘Electricity prices for household consumers - bi-annual data (from 2007 onwards)’. el_data = el_data[((el_data['tax']=='I_TAX')
&(el_data['currency']=='EUR')
&(el_data['nrg_cons']=='KWH5000-14999'))]import eurostat
toc = eurostat.get_toc_df()
toc| title | code | type | last update of data | last table structure change | data start | data end | |
|---|---|---|---|---|---|---|---|
| 0 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_NL | dataset | 2010-02-26T23:00:00+0100 | 2023-07-28T23:00:00+0200 | 1997-Q1 | 2022-Q4 |
| 1 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_NO | dataset | 2010-02-26T23:00:00+0100 | 2023-07-28T23:00:00+0200 | 2002-Q1 | 2021-Q4 |
| 2 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_PL | dataset | 2023-09-12T11:00:00+0200 | 2023-09-12T11:00:00+0200 | 2004-Q1 | 2023-Q1 |
| 3 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_PT | dataset | 2023-09-19T11:00:00+0200 | 2023-09-19T11:00:00+0200 | 2000-Q1 | 2023-Q1 |
| 4 | Passengers (excluding cruise passengers) trans... | MAR_PA_QM_SE | dataset | 2010-02-26T23:00:00+0100 | 2023-07-28T23:00:00+0200 | 1997-Q1 | 2022-Q4 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 7545 | Percentage of letters delivered on-time (USP u... | POST_CUBE1_X$POST_QOS_1 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
| 7546 | Postal services | POST_CUBE1_X | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | 2012 | 2021 |
| 7547 | Number of enterprises providing postal services | POST_CUBE1_X$NUM701 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
| 7548 | Access points (USP under direct or indirect d... | POST_CUBE1_X$POST_ACC_1 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
| 7549 | Domestic postal traffic, letter mail and parce... | POST_CUBE1_X$POST_DTR_1 | dataset | 2023-05-23T08:18:37Z | 2023-05-10T10:54:33Z | None | None |
7550 rows × 7 columns
Finner alle tabeller med ‘electricity’ i seg:
toc[['electricity prices' in i.lower() for i in toc['title']]]| title | code | type | last update of data | last table structure change | data start | data end | |
|---|---|---|---|---|---|---|---|
| 609 | Electricity prices for household consumers - b... | NRG_PC_204 | dataset | 2023-10-17T11:00:00+0200 | 2023-10-03T23:00:00+0200 | 2007-S1 | 2023-S1 |
| 611 | Electricity prices components for household co... | NRG_PC_204_C | dataset | 2023-10-10T23:00:00+0200 | 2023-06-02T23:00:00+0200 | 2017 | 2022 |
| 613 | Electricity prices for domestic consumers - bi... | NRG_PC_204_H | dataset | 2021-05-28T23:00:00+0200 | 2021-05-28T23:00:00+0200 | 1985-S1 | 2007-S2 |
| 617 | Electricity prices for non-household consumers... | NRG_PC_205 | dataset | 2023-10-17T11:00:00+0200 | 2023-10-03T23:00:00+0200 | 2007-S1 | 2023-S1 |
| 619 | Electricity prices components for non-househol... | NRG_PC_205_C | dataset | 2023-10-10T23:00:00+0200 | 2023-06-02T23:00:00+0200 | 2017 | 2022 |
| 621 | Electricity prices for industrial consumers - ... | NRG_PC_205_H | dataset | 2021-05-28T23:00:00+0200 | 2021-05-28T23:00:00+0200 | 1985-S1 | 2007-S2 |
| 4291 | Electricity prices by type of user | TEN00117 | dataset | 2023-10-17T11:00:00+0200 | 2023-10-17T11:00:00+0200 | 2011 | 2022 |
Koden for relevante data er ‘NRG_PC_205’:
el_data = eurostat.get_data_df('NRG_PC_204')
el_data| freq | product | nrg_cons | unit | tax | currency | geo\TIME_PERIOD | 2007-S1 | 2007-S2 | 2008-S1 | ... | 2018-S2 | 2019-S1 | 2019-S2 | 2020-S1 | 2020-S2 | 2021-S1 | 2021-S2 | 2022-S1 | 2022-S2 | 2023-S1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | S | 6000 | KWH1000-2499 | KWH | I_TAX | EUR | AL | NaN | NaN | NaN | ... | 0.0910 | 0.0920 | 0.0933 | 0.0922 | 0.0920 | 0.0925 | 0.0937 | 0.0941 | 0.0976 | 0.1010 |
| 1 | S | 6000 | KWH1000-2499 | KWH | I_TAX | EUR | AT | NaN | 0.2008 | 0.2005 | ... | 0.2411 | 0.2426 | 0.2453 | 0.2511 | 0.2567 | 0.2650 | 0.2787 | 0.2616 | 0.2614 | 0.2988 |
| 2 | S | 6000 | KWH1000-2499 | KWH | I_TAX | EUR | BA | NaN | NaN | NaN | ... | 0.0977 | 0.0979 | 0.0980 | 0.0975 | 0.1007 | 0.0980 | 0.0970 | 0.0996 | 0.1003 | 0.1043 |
| 3 | S | 6000 | KWH1000-2499 | KWH | I_TAX | EUR | BE | NaN | 0.1867 | 0.2172 | ... | 0.3180 | 0.3075 | 0.3099 | 0.2998 | 0.2938 | 0.2910 | 0.3161 | 0.3633 | 0.4586 | 0.4559 |
| 4 | S | 6000 | KWH1000-2499 | KWH | I_TAX | EUR | BG | NaN | 0.0721 | 0.0731 | ... | 0.1004 | 0.1003 | 0.0994 | 0.1017 | 0.1021 | 0.1045 | 0.1104 | 0.1110 | 0.1147 | 0.1145 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2191 | S | 6000 | TOT_KWH | KWH | X_VAT | PPS | RS | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | 0.1309 | 0.1307 | 0.1420 | 0.1497 |
| 2192 | S | 6000 | TOT_KWH | KWH | X_VAT | PPS | SE | NaN | NaN | NaN | ... | NaN | NaN | NaN | 0.0983 | 0.1029 | 0.1046 | 0.1248 | 0.1068 | 0.1330 | 0.1465 |
| 2193 | S | 6000 | TOT_KWH | KWH | X_VAT | PPS | SI | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | 0.1583 | 0.1299 | 0.1915 | 0.1964 |
| 2194 | S | 6000 | TOT_KWH | KWH | X_VAT | PPS | SK | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | 0.1678 | 0.1847 | 0.1959 | 0.1919 |
| 2195 | S | 6000 | TOT_KWH | KWH | X_VAT | PPS | TR | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | 0.1836 | 0.2987 | NaN | NaN |
2196 rows × 40 columns
Vi ser på pris inkludert skatt i Euro i intervallet 5000-14999:
el_data_fltrd = el_data[((el_data['tax']=='I_TAX')&(el_data['currency']=='EUR')&(el_data['nrg_cons']=='KWH5000-14999'))]
unwanted=el_data_fltrd['geo\\TIME_PERIOD'].isin(['EA18','EA19','EU27_2007','EU27_2020','EA18','EA18'])
el_data_fltrd2 = el_data_fltrd[unwanted==False]
el_data_fltrd2 = el_data_fltrd2.rename(columns={'geo\\TIME_PERIOD':'country'})
el_data_fltrd2 = el_data_fltrd2.set_index('country')
el_data_fltrd2 = el_data_fltrd2.iloc[:,6:]
el_data_fltrd2 = el_data_fltrd2.transpose()
el_data_fltrd2 = 100*el_data_fltrd2.div(gdp_data_fltrd3.iloc[0])
el_data_fltrd2| country | AL | AT | BA | BE | BG | CH | CY | CZ | DE | DK | ... | RO | RS | SE | SI | SK | TR | UA | UK | US | XK |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2007-S1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.000445 | 0.000715 | NaN | ... | NaN | NaN | 0.000496 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2007-S2 | NaN | 0.000562 | NaN | 0.000596 | 0.000857 | NaN | 0.000694 | 0.000458 | 0.000755 | 0.000759 | ... | 0.001454 | NaN | 0.000525 | 0.000524 | 0.000807 | 0.000919 | NaN | 0.000500 | NaN | NaN |
| 2008-S1 | NaN | 0.000571 | NaN | 0.000650 | 0.000851 | NaN | 0.000786 | 0.000572 | 0.000753 | 0.000837 | ... | 0.001320 | NaN | 0.000530 | 0.000547 | 0.000876 | 0.001018 | NaN | 0.000506 | NaN | NaN |
| 2008-S2 | NaN | 0.000577 | NaN | 0.000715 | 0.000986 | NaN | 0.000926 | 0.000583 | 0.000772 | 0.000891 | ... | 0.001396 | NaN | 0.000540 | 0.000560 | 0.000957 | 0.001247 | NaN | 0.000521 | NaN | NaN |
| 2009-S1 | NaN | 0.000606 | NaN | 0.000626 | 0.000980 | NaN | 0.000708 | 0.000598 | 0.000804 | 0.000858 | ... | 0.001191 | NaN | 0.000490 | 0.000649 | 0.001091 | 0.001167 | NaN | 0.000488 | NaN | NaN |
| 2009-S2 | NaN | 0.000611 | NaN | 0.000605 | 0.000992 | NaN | 0.000729 | 0.000630 | 0.000810 | 0.000807 | ... | 0.001195 | NaN | 0.000509 | 0.000631 | 0.001146 | 0.001203 | NaN | 0.000466 | NaN | NaN |
| 2010-S1 | NaN | 0.000618 | NaN | 0.000637 | 0.000980 | NaN | 0.000795 | 0.000608 | 0.000848 | 0.000824 | ... | 0.001280 | NaN | 0.000569 | 0.000655 | 0.000999 | 0.001369 | NaN | 0.000462 | NaN | NaN |
| 2010-S2 | NaN | 0.000611 | NaN | 0.000649 | 0.001002 | NaN | 0.000884 | 0.000629 | 0.000868 | 0.000838 | ... | 0.001314 | NaN | 0.000607 | 0.000668 | 0.001072 | 0.001402 | NaN | 0.000488 | NaN | NaN |
| 2011-S1 | 0.002400 | 0.000629 | NaN | 0.000709 | 0.000992 | NaN | 0.000877 | 0.000683 | 0.000909 | 0.000907 | ... | 0.001351 | NaN | 0.000643 | 0.000683 | 0.001104 | 0.001238 | NaN | 0.000473 | NaN | NaN |
| 2011-S2 | 0.002410 | 0.000621 | NaN | 0.000688 | 0.001045 | NaN | 0.001052 | 0.000670 | 0.000918 | 0.000931 | ... | 0.001370 | NaN | 0.000630 | 0.000698 | 0.001133 | 0.001164 | NaN | 0.000527 | NaN | NaN |
| 2012-S1 | 0.002423 | 0.000622 | 0.001309 | 0.000711 | 0.000994 | NaN | 0.001194 | 0.000698 | 0.000934 | 0.000937 | ... | 0.001327 | NaN | 0.000608 | 0.000720 | 0.001120 | 0.001339 | NaN | 0.000556 | NaN | NaN |
| 2012-S2 | 0.002431 | 0.000639 | 0.001323 | 0.000719 | 0.001164 | NaN | 0.001278 | 0.000699 | 0.000963 | 0.000930 | ... | 0.001362 | NaN | 0.000636 | 0.000721 | 0.001129 | 0.001505 | NaN | 0.000602 | NaN | NaN |
| 2013-S1 | 0.002408 | 0.000658 | 0.001312 | 0.000727 | 0.001114 | NaN | 0.001192 | 0.000714 | 0.001054 | 0.000810 | ... | 0.001651 | 0.000755 | 0.000630 | 0.000737 | 0.001101 | 0.001522 | NaN | 0.000585 | NaN | NaN |
| 2013-S2 | 0.002404 | 0.000645 | 0.001327 | 0.000734 | 0.001076 | NaN | 0.001091 | 0.000698 | 0.001052 | 0.000793 | ... | 0.001587 | 0.000815 | 0.000627 | 0.000755 | 0.001112 | 0.001339 | NaN | 0.000617 | NaN | NaN |
| 2014-S1 | 0.002408 | 0.000644 | 0.001325 | 0.000693 | 0.001005 | NaN | 0.000984 | 0.000610 | 0.001072 | 0.000822 | ... | 0.001589 | 0.000813 | 0.000581 | 0.000742 | 0.000983 | 0.001216 | NaN | 0.000644 | NaN | NaN |
| 2014-S2 | 0.002417 | 0.000632 | 0.001327 | 0.000658 | 0.001059 | NaN | 0.001037 | 0.000606 | 0.001071 | 0.000820 | ... | 0.001562 | 0.000796 | 0.000574 | 0.000745 | 0.000997 | 0.001344 | NaN | 0.000678 | NaN | NaN |
| 2015-S1 | 0.001692 | 0.000620 | 0.001339 | 0.000708 | 0.001128 | NaN | 0.000839 | 0.000604 | 0.001061 | 0.000823 | ... | 0.001627 | 0.000777 | 0.000553 | 0.000716 | 0.000965 | 0.001384 | NaN | 0.000715 | NaN | NaN |
| 2015-S2 | 0.001706 | 0.000611 | 0.001354 | 0.000774 | 0.001158 | NaN | 0.000810 | 0.000614 | 0.001059 | 0.000811 | ... | 0.001651 | 0.000861 | 0.000553 | 0.000732 | 0.000971 | 0.001243 | NaN | 0.000752 | NaN | NaN |
| 2016-S1 | 0.001717 | 0.000624 | 0.001364 | 0.000857 | 0.001141 | NaN | 0.000648 | 0.000625 | 0.001065 | 0.000869 | ... | 0.001534 | 0.000849 | 0.000554 | 0.000721 | 0.000923 | 0.001293 | NaN | 0.000671 | NaN | NaN |
| 2016-S2 | 0.001740 | 0.000615 | 0.001386 | 0.000919 | 0.001128 | NaN | 0.000712 | 0.000625 | 0.001068 | 0.000865 | ... | 0.001533 | 0.000872 | 0.000577 | 0.000728 | 0.000983 | 0.001228 | NaN | 0.000637 | NaN | NaN |
| 2017-S1 | 0.001758 | 0.000596 | 0.001420 | 0.000951 | 0.001141 | NaN | 0.000796 | 0.000631 | 0.001089 | 0.000856 | ... | 0.001494 | 0.000881 | 0.000557 | 0.000717 | 0.000896 | 0.001070 | NaN | 0.000592 | NaN | NaN |
| 2017-S2 | 0.001783 | 0.000606 | 0.001425 | 0.000960 | 0.001190 | NaN | 0.000802 | 0.000654 | 0.001089 | 0.000836 | ... | 0.001596 | 0.000924 | 0.000587 | 0.000717 | 0.000914 | 0.000978 | NaN | 0.000628 | NaN | NaN |
| 2018-S1 | NaN | 0.000600 | 0.001430 | 0.000948 | 0.001172 | NaN | 0.000792 | 0.000672 | 0.001059 | 0.000866 | ... | 0.001651 | 0.000931 | 0.000566 | 0.000711 | 0.000984 | 0.000918 | NaN | 0.000637 | NaN | NaN |
| 2018-S2 | 0.001896 | 0.000616 | 0.001446 | 0.000987 | 0.001218 | NaN | 0.000933 | 0.000683 | 0.001063 | 0.000914 | ... | 0.001629 | 0.000944 | 0.000630 | 0.000730 | 0.000937 | 0.000870 | NaN | 0.000689 | NaN | NaN |
| 2019-S1 | 0.001917 | 0.000622 | 0.001436 | 0.000954 | 0.001194 | NaN | 0.000945 | 0.000753 | 0.001089 | 0.000854 | ... | 0.001720 | 0.000932 | 0.000606 | 0.000721 | 0.001001 | 0.000864 | NaN | 0.000715 | NaN | NaN |
| 2019-S2 | 0.001944 | 0.000638 | 0.001455 | 0.000966 | 0.001131 | NaN | 0.000958 | 0.000771 | 0.001002 | 0.000832 | ... | 0.001818 | 0.000964 | 0.000621 | 0.000745 | 0.001018 | 0.001061 | NaN | 0.000753 | NaN | NaN |
| 2020-S1 | 0.001921 | 0.000647 | 0.001454 | 0.000943 | 0.001159 | NaN | 0.000919 | 0.000782 | 0.001084 | 0.000798 | ... | 0.001849 | 0.000976 | 0.000545 | 0.000673 | 0.001094 | 0.001016 | NaN | 0.000754 | NaN | NaN |
| 2020-S2 | 0.001917 | 0.000667 | 0.001498 | 0.000915 | 0.001149 | NaN | 0.000719 | 0.000763 | 0.001061 | 0.000707 | ... | 0.001823 | 0.000981 | 0.000591 | 0.000757 | 0.001124 | 0.000834 | NaN | NaN | NaN | NaN |
| 2021-S1 | 0.001927 | 0.000677 | 0.001463 | 0.000926 | 0.001192 | NaN | 0.000841 | 0.000767 | 0.001108 | 0.000665 | ... | 0.001911 | 0.001051 | 0.000605 | 0.000730 | 0.001076 | 0.000847 | NaN | NaN | NaN | NaN |
| 2021-S2 | 0.001952 | 0.000697 | 0.001439 | 0.001051 | 0.001308 | NaN | 0.000985 | 0.000925 | 0.001114 | 0.000858 | ... | 0.001992 | 0.001075 | 0.000752 | 0.000753 | 0.001055 | 0.000801 | NaN | NaN | NaN | NaN |
| 2022-S1 | 0.001960 | 0.000696 | 0.001484 | 0.001228 | 0.001304 | NaN | 0.001119 | 0.001094 | 0.001134 | 0.001227 | ... | 0.002944 | 0.001063 | 0.000632 | 0.000623 | 0.001174 | 0.001016 | NaN | NaN | NaN | NaN |
| 2022-S2 | 0.002033 | 0.000776 | 0.001496 | 0.001631 | 0.001387 | NaN | 0.001452 | 0.001062 | 0.001152 | 0.001756 | ... | 0.004241 | 0.001161 | 0.000814 | 0.000886 | 0.001237 | NaN | NaN | NaN | NaN | NaN |
| 2023-S1 | 0.002104 | 0.000909 | 0.001543 | 0.001532 | 0.001364 | NaN | 0.001615 | 0.001462 | 0.001458 | 0.001303 | ... | 0.004558 | 0.001288 | 0.000775 | 0.000884 | 0.001231 | 0.001016 | NaN | NaN | NaN | NaN |
33 rows × 47 columns
ax=el_data_fltrd2.plot(alpha=0.3,figsize=(20, 10))
ax.legend(loc='upper left',frameon=False,ncol=4)<matplotlib.legend.Legend at 0x18439b5fe90>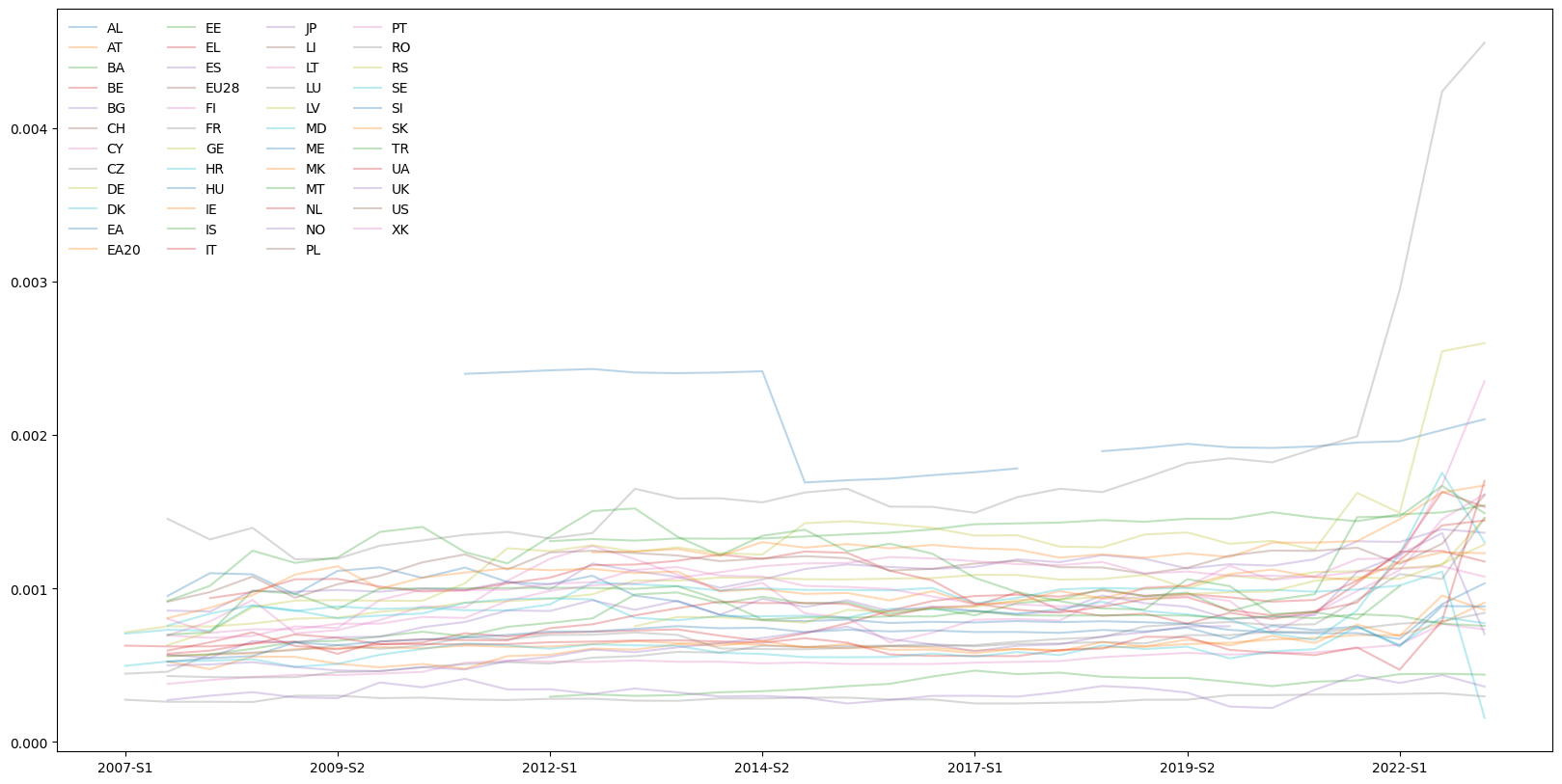
def thick_line(symbol,ax):
labels=[i._label for i in ax.lines] #makes a list of symbols in the order of lines in the axis object
i=labels.index(symbol) #identifies at which position symbol is located
ax.lines[i].set_linewidth(5) #sets the line with of the line at position i to 5
ax.lines[i].set_alpha(1) #removes transparancy of the line at position i to 5
thick_line('DE',ax)
thick_line('NO',ax)
thick_line('EU28',ax)
ax.legend(loc='upper left',frameon=False,ncol=4)
ax.figure